
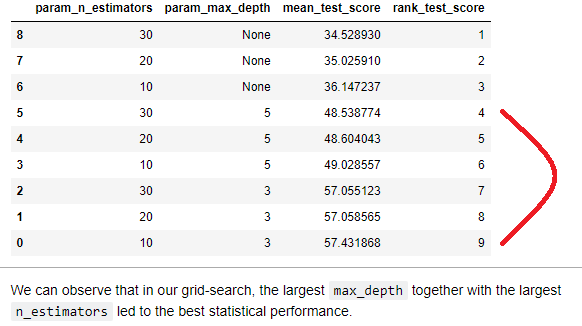
Not sure whether I am just reading this wrong but there seems to be an error in the first lecture. It says the best model is the one with the the largest max depth (=5) and n_estimators (=30), when in fact that is a combination that only leads to mediocre performance. It is the n_estimators = 10 and the max_depth = 3 that leads to the best performance…?
PS: I reset the notebook and restarted the kernel before running this.