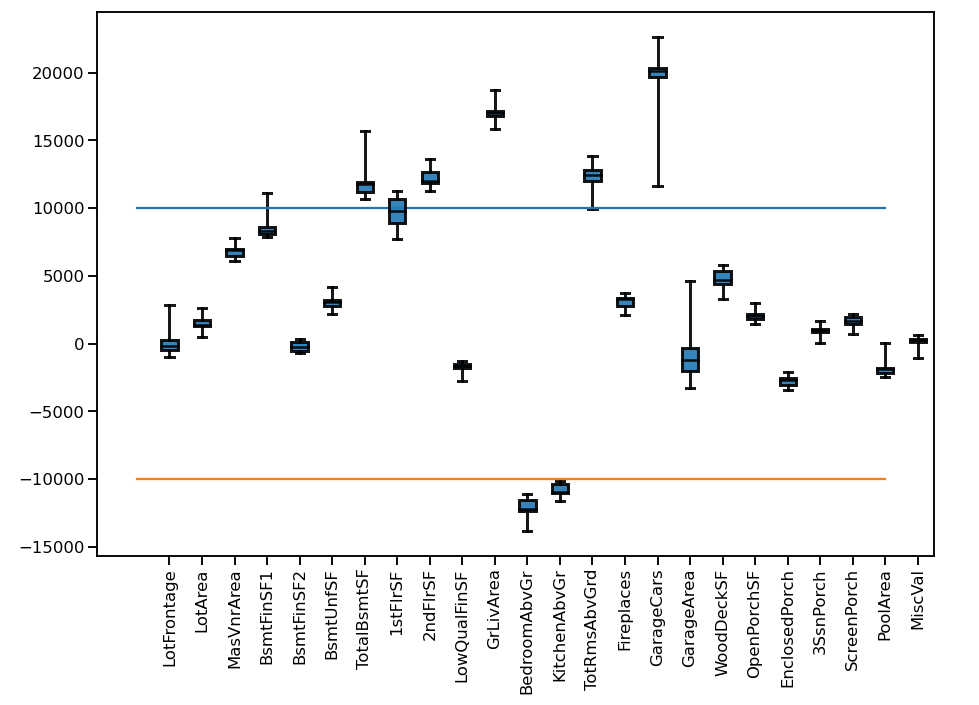
Hi,
in question 1 I already get the order of magnitude in the ballpark of 1e4. See attached snpshots.
Did i overlook something?
thanks,
Pedro

a

Hi,
in question 1 I already get the order of magnitude in the ballpark of 1e4. See attached snpshots.
Did i overlook something?
thanks,
Pedro
We had a discussion on a previous post where we saw that imputing and then scaling the data would give a different magnitude than scaling and imputing, while they should be almost equivalent.
We change the question and explicitly ask for scaling and then imputing the dataset to get the right magnitude.
Could you provide your pipeline to make sure that you have the right sequence of transformers?
Hello,
thanks for the super fast feedback. The pipeline is copied below
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn import set_config
set_config(display='diagram')
si=SimpleImputer()
ss=StandardScaler()
lr=LinearRegression()
model=make_pipeline(si,ss,lr)
model
so i guess that goes in accordance to what you have described.
My question is then: shouldn’t in general one first impute (fill in missing values) and only then start transforming the values themselves?
Indeed not because the imputed strategy might have an effect on the scaling (imagine that impute with -1 and then compute statistics).
What we asked is to put the scaler first and then the imputer.
It’s very clear to me now  Thanks a lot!
Thanks a lot!
Pedro