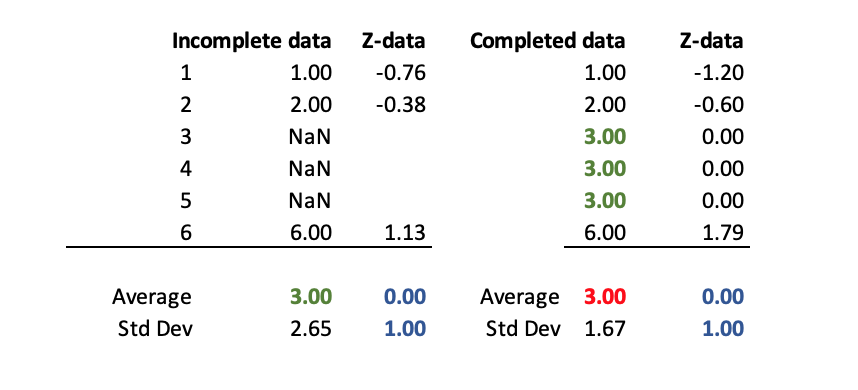
Let’s simplify things for the moment and assume that scikit-learn transformers omit missing values when computing statistics that is indeed the case for the StandardScaler
Let’s discuss the pipeline make_pipeline(SimpleImputer(strategy="constant", fill_value=10_000), StandardScaler()). Here, I specifically impute with a large value to illustrate the drawback of using this approach. Indeed, we impute with an extreme value. StandardScaler will use these imputed values to compute the mean and standard deviation. It could be an issue depending on the underlying distribution of the feature.
In the contrary, make_pipeline(StandardScaler(), SimpleImputer(strategy="constant", fill_value=10_000)), has the advantage that feature values will be scaled omitting missing values and then imputed. Thus, the strategy used for imputing will not have an impact on the statistics computation.
Thus, when possible, it will be a better practice.
However, not all transformers in scikit-learn omit missing values (to my knowledge, all scalers do). So you might need to use the first case sometimes. However, we are currently working in scikit-learn such that missing values can be ignored in the preprocessing for the transformers that do not support it yet.