
Hi, I’d like to ask a question on “boosting for classification”. After the classification model has been trained, when we want to do prediction on a new data point, what’s going to happen? Will there be a voting mechanism like what was presented in the previous section on bagging?
For example, here we want to predict the class of the red mark:
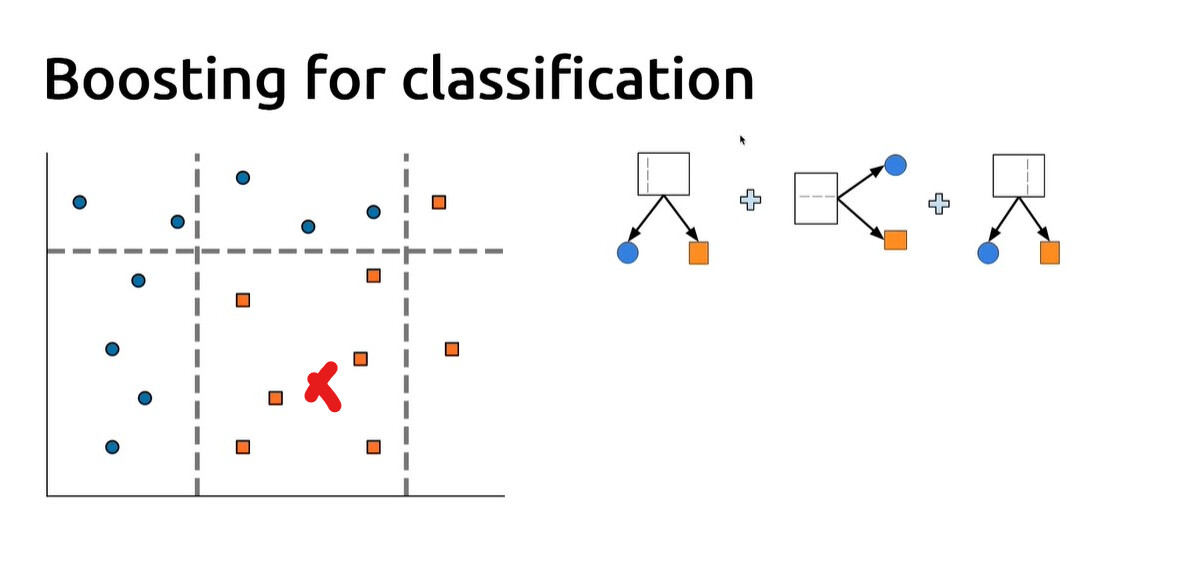
The left hand model predicts “orange”, the model at the center predicts “orange”, and the right hand side model predicts “blue”. So we have 2 votes for “orange” vs 1 vote for “blue”, hence the final prediction is “orange”. Does it work in this way? Thank you!