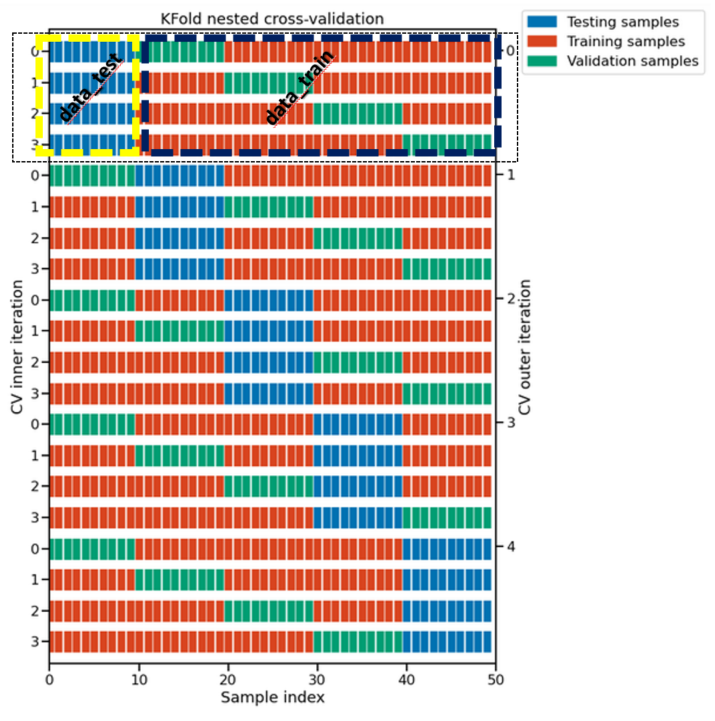
I tried to do the exercise in a more generic way and find the the best model results through nested cross validation.
So, after I did all the preprocessing steps, this is my training-validation-test step:
params = {
"logisticregression__C": loguniform(0.001, 10),
"columntransformer__standard_scaler__with_mean": (True, False),
"columntransformer__standard_scaler__with_std": (True, False)
}
# Write your code here.
model_randomised_search = RandomizedSearchCV(model, param_distributions=params, cv=2)
cv_results = cross_validate(model_randomised_search, data, target, cv=5, n_jobs=2, return_estimator=True)
pd.DataFrame(cv_results)
When the last line of my script runs, it shows me a dataframe with 5 rows and five test_scores which are all around 85%; however, when I run model_randomised_search.best_params_ it gives me an attribution error that AttributeError: 'RandomizedSearchCV' object has no attribute 'best_params_'
I cannot understand why do I receive such an error?
P.S. I also did not do any train-test split since I am using the nested cross_validation.