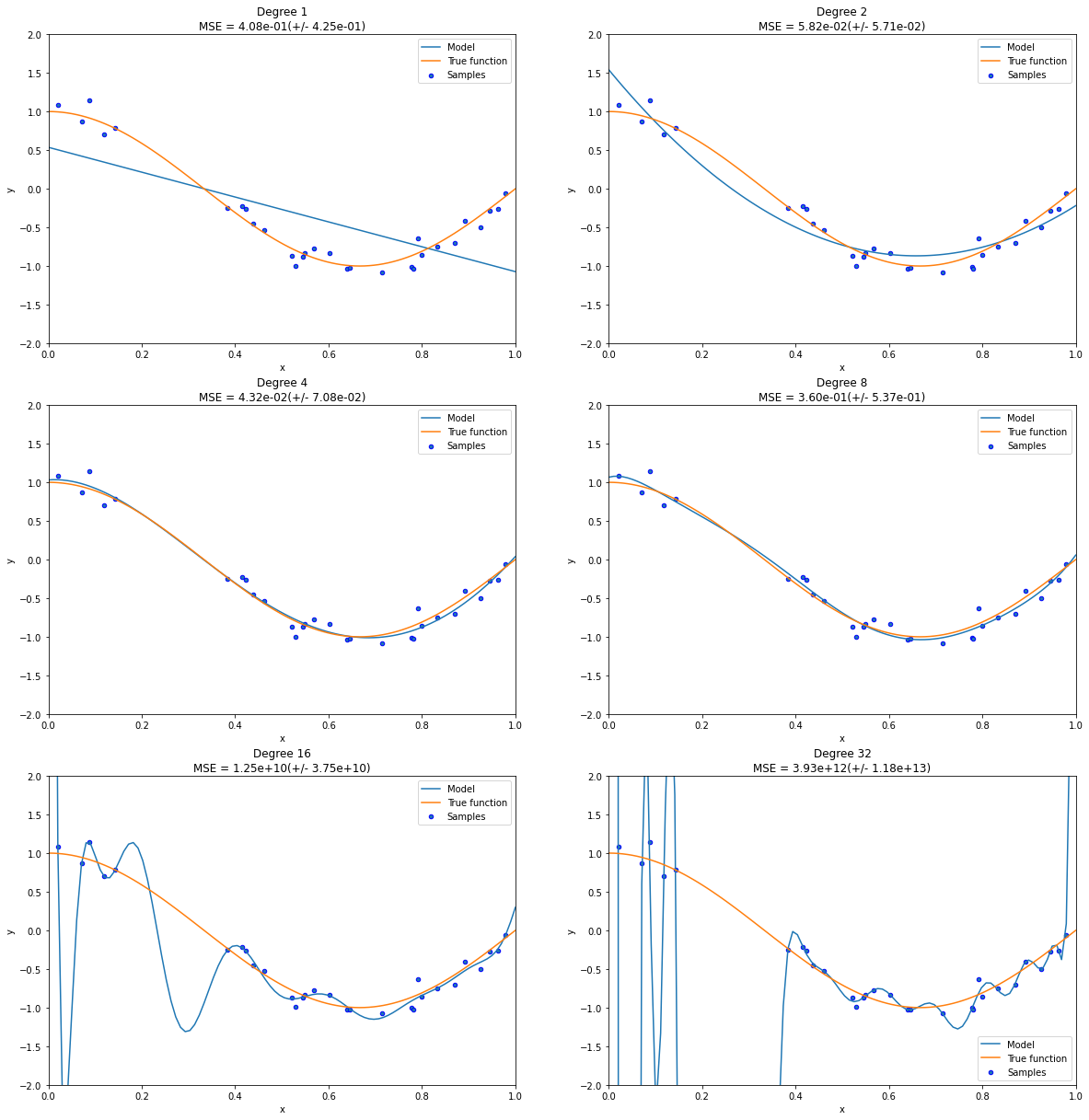
By looking at the match with the ground truth curve, I would also say that 2 is (slightly) underfitting, compared to the the degree 4 model that is a very good match.
The MSE seems to be quite higher than for the degree 4 model but it’s not possible to tell if the degree 4 model’s improvement is related to matching unstructured noise in the training. To conclude about under fitting vs over fitting and the best trade-off without having access to the ground truth orange curve, one would require to use cross-validation to compute both the cross-validated train and test scores for each model and look at the gap between the two and use the model with the best test scores to identify the best trade-off.