
Looking at the solution I see
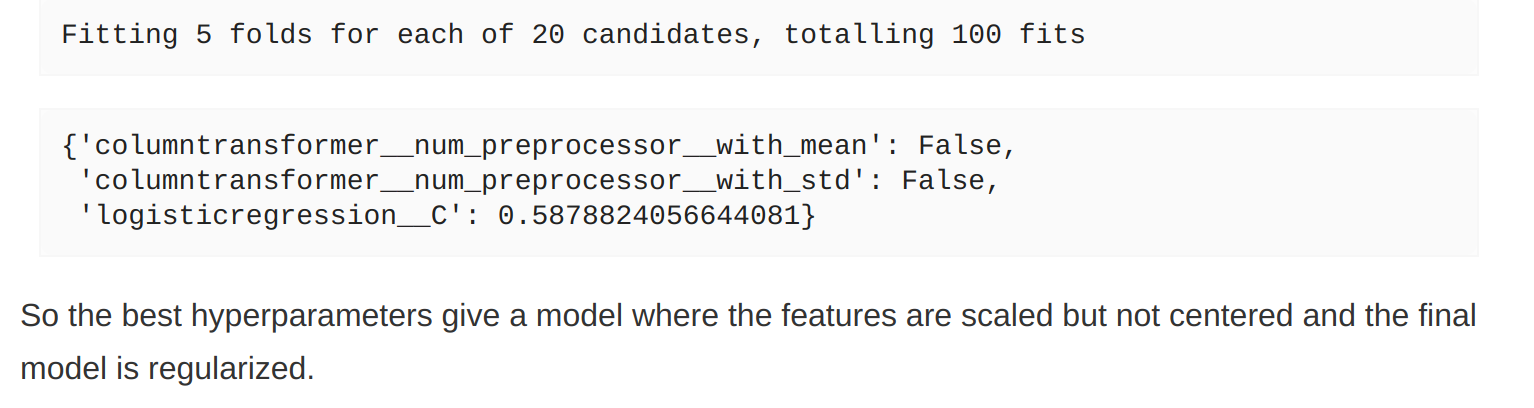
The results of the search and the prose below appear to disagree? (I would have expected with_std to be True if scaling yields better results?
The parallel plot also agrees with the prose paragraph (the best models seem to be scaled).
What gives?
Thanks!
(doing the search on my own also resulted in a model whose best-performing value for with_std was False)