
I’m confused with the answers to the last question.
Here is what I get from my code, which is basically the same as with the provided answer.
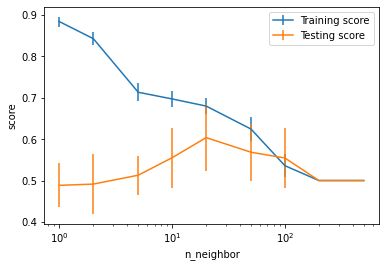
Now from what I understand, the training score is very high between 1 and 10 neighbors, while the test score is low. It means that my model is overfitting the training set, but does not perform well on the test set, am I right ? If so I don’t understand the answers to the test which say the opposite. The same goes when using a large number of neighbors. For me both scores are low, so we are underfitting. Then between 10 and 100 we have an in-between situation.
Could you clarify it for me please ? And if I’m confused, probably others will be.
Wether I’m right or wrong, I think there should be a self-explanatory figure in the answer of the last question, showing why and where it is overfitting or underfitting. This would remove any ambiguity.
