
Hello, one question: In Example 1, the degree-9-polynomial was the “bad” choice because of overfitting. In Example 2, it was the “best” choice. I am a bit confused: Is the degree-9-polynomial also the real data-generating process in example 1? If not, I would recommend, for didactical reasons, not to choose that case as the best choice for example 2. But maybe I misunderstood it.
Or is this the message: Even if the real data-generating process is more complex: the error curves may be misleading because of too limited data. Choose, as long as you have limited data, a simpler model?
I am not sure about what examples 1 and 2 are referring to, so I will paste one screenshot and refer to it:
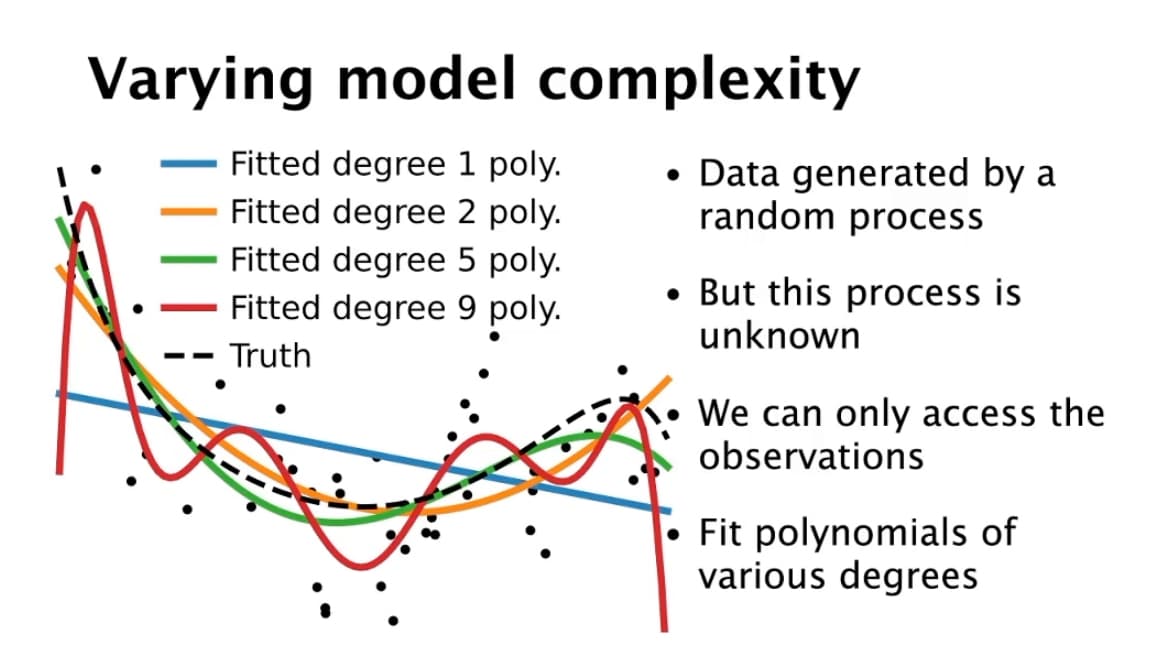
In true generative model (dash black line) is a polynomial of 9th degree. However, the observed data (the black dots) are a realisation of this generative model with additional Gaussian noise.
What we can see by fitting different models on the observed data is that the model with 9 degrees is overfitting even though it corresponds to the complexity of the original generative model. We can infer that this failure is due to the additive noise. A model with a lower polynomial degree will alleviate the overfitting at the cost of the model not being expressive enough.
I find it interesting to notice the gap between the true generative model, the observed data, and the best model fitted. I agree that it is confusing but it shows the tricky part.
I can only come up with the answer “it depends”  I can highlight two different wishes when one tries to build a predictive model:
I can highlight two different wishes when one tries to build a predictive model:
- One wants to get the best predictive model possible that make the best predictions meaning that the model should make the least error possible on the available data (of course through cross-validation).
- One wants to get the simplest model possible, with the lowest prediction error possible but such that we have an interest in understanding the decision mechanism of the model.
I assume that in real life we always want a trade-off between a complex model that predict well and is interpretable (of some sort).
NB: I am adding this example outside of the main discussion because it is not exactly used in the context of machine learning but I find it quite interesting. It comes from a discussion given in “The Limits to Growth” book where the authors come up with a model called “World3” (a Python version is available there). They explain the choice done for their model: they are not interested in predicting the true future but instead to have a simplistic and understandable approach to the dynamic of the physical system itself. Therefore, they want a simple model and make several scenarios instead of being able to forecast the future as accurately as possible.
3 Likes
Thank you for the reply. Yes that is interesting: Even choosing the true model leads to bad results sometimes.