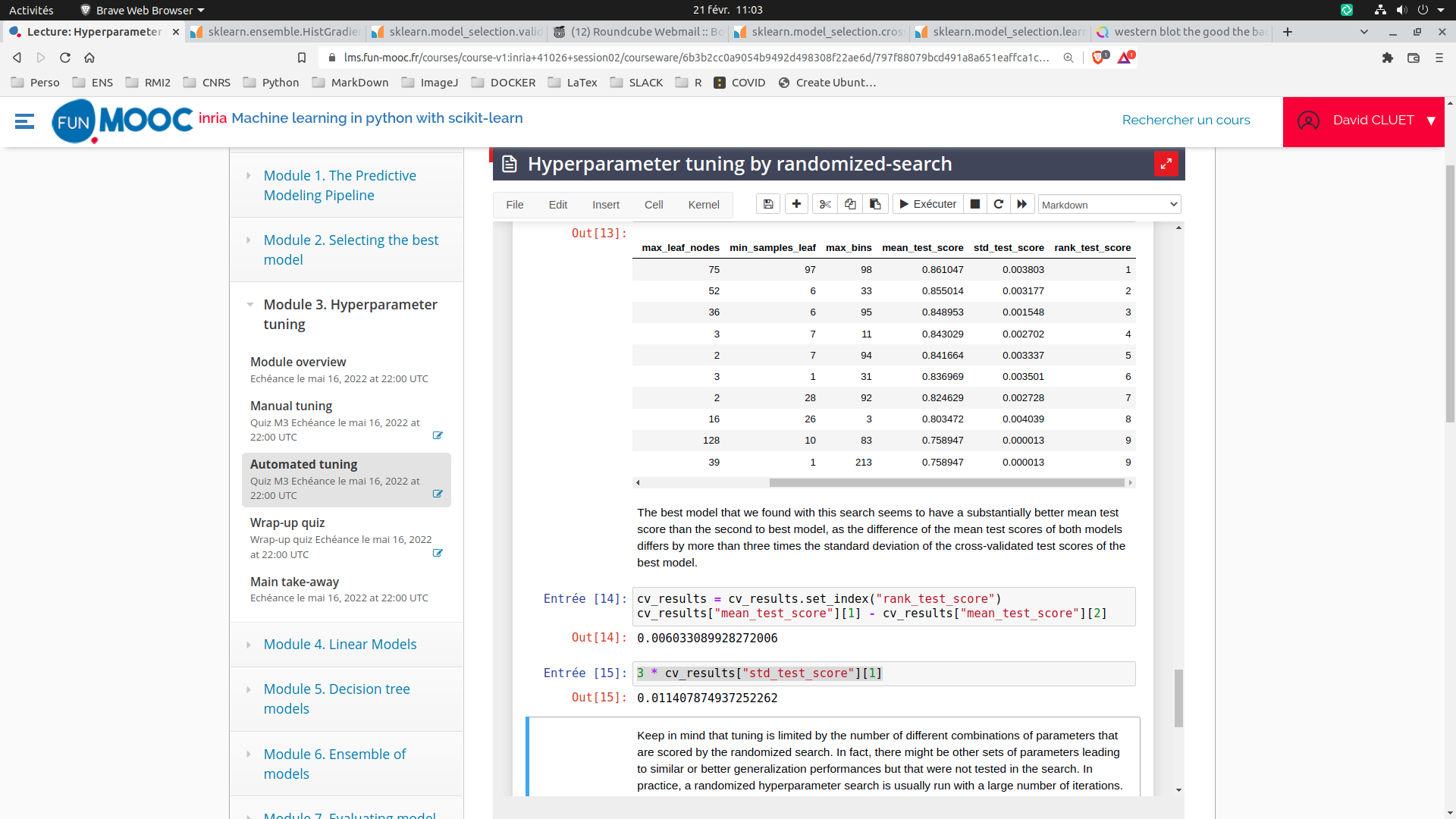
If you know that the two random variables are independent and Gaussian, then you could do a statistical significance test based the standard error of the mean. But unfortunately, cross-validation scores for 2 different models on the same CV folds are not independent (often non-Gaussian), so it’s more complicated.
Precise statistical model evaluation is beyond the scope of this MOOC but if you are interested you might want to have a look at:
and the references therein. In the context of this MOOC, we tried to find cases where the models to compare are either strikingly different to avoid such problems. But this is often the case in practice that the differences between too good models are not very meaningful.