
If our model learnt from the training data, why is the score of prediction on the training data still 82%…I was thinking we’d get something close to 100% since it memorized that dataset.
It is true that we could expect better statistical performance. To understand why we don’t get better accuracy, we should look at the data themselves.
Indeed, there are some duplicated samples that are assigned to different classes. I did a quick example for one specific sample:
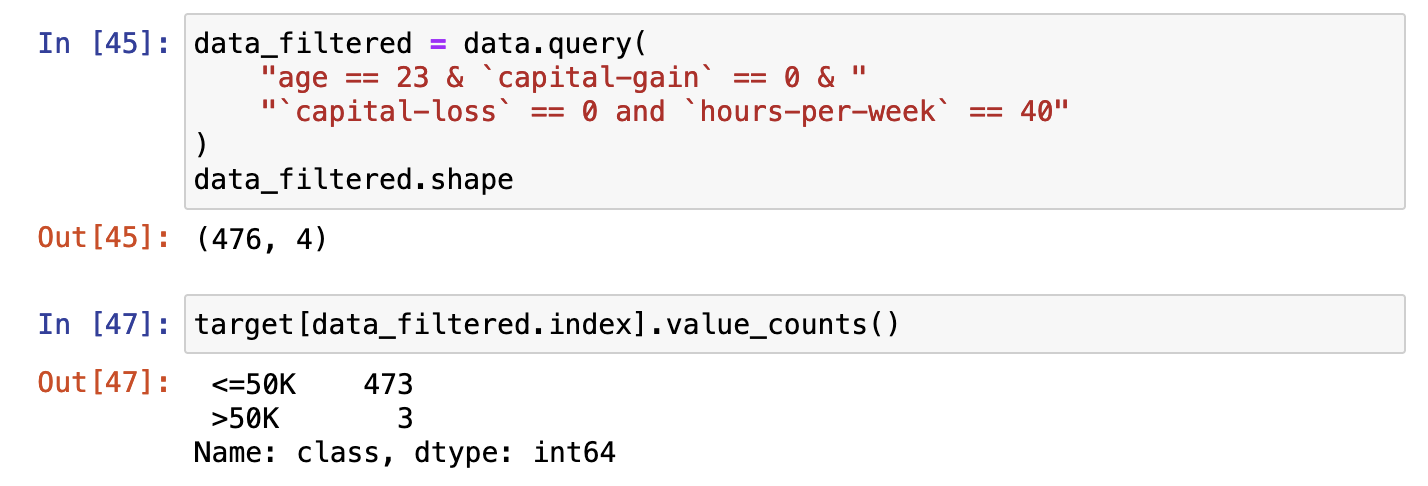
It means that for this specific sample, we will make for sure 3 errors. Applying the same approach for all possible samples, we will end up making quite a lot of mistakes then.
The reason for having that many duplicates here are due to the fact that we are using a subset of features (only the numerical one).
1 Like