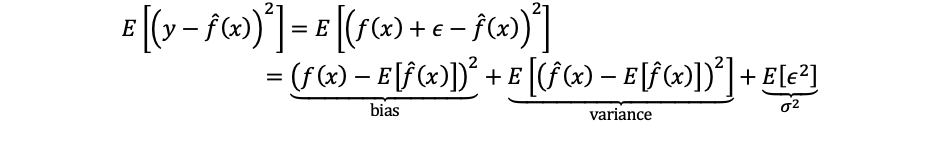Hi,
Cross-validation is definitely used to avoid overfitting! That helps for a better generalization, doesn’t that?

Hi,
Cross-validation is definitely used to avoid overfitting! That helps for a better generalization, doesn’t that?
I had a response about avoiding over-fitting in question 7 about the pipeline, but not in question 6 (are the possible answers randomized?).
I note that the concept of over-fitting has not been introduced at this point in the course, so it doesn’t make much sense to have this as a possible answer.
Hi @DavidPowell,
Overfitting is a situation where we do very well (for example a high accuracy score) on the data that we have in hands but poorly on new unseen data. That is the reason why we split the data into two training and test (also called validation) sets in the first place, so that we can detect overfitting. We don’t want our model to be specialized (overfitted) with some training data but rather more generalized so that we can apply it on new data.
Cross-validation is one step further where we do the training-validation, not only on one set but on a defined number of folds of the set. Our model learns on multiple sets instead of one set and this method definitely mitigates overfitting and so yields a better generalization performance.
There is a section about overfitting in the next module. Meanwhile, we have some information about cross-validation by scikit-learn here.
Cheers!
A predictive model is the piece of the framework of machine-learning that will under-fit, generalize, or over-fit. Evaluating a predictive model is the step that allows detecting whether or not a model under-fit, generalize, or over-fit. Cross-validation is such an evaluation technique. Therefore, cross-validation does not make a model do over-fit less.
To go more in details (that comes in later chapter), we have parameters (called hyper-parameters) that allows to reduce or increase the model complexity and thus its capacity to overfit. Cross-validation is then the technique to assess the score and thus conclude on the impact of the hyper-parameter on the model complexity.
@DavidPowell I doubled check. Indeed we don’t introduce the over-fitting at this stage but the question does not refer to the concept. We only refer to “generalization performance” which was introduced.
(The questions are not randomized  )
)
Guillaume’s answer is correct. The most important point in Guillaume’s answer is that cross-validation does not help get better generalization by itself, but it makes it possible to quantify how much a model generalizes.
Later in this MOOC we will see that to help get better generalization you can: adjust the hyper-parameters (or change the model class), increase the number of labeled samples in the training set or remove noisy, uninformative features (columns). And cross-validation is the tool to measure how each of those choice can help or not.
We can probably improve the explanations of the solution of this quiz question based on the replies of this thread.
Thank you for your feedback.
I believe we don’t have the same terms here.
In my point of view, a model either underfit, or fit well (instead of generalize), or overfit. I would say that if you underfit, you also have a good generalization but with a poor performance. On the other hand, if you overfit, you have a very good performance on the training data but poor performance on the test/validation data, so a poor generalization. What we just want is the model to properly fit, which gives the optimal model for a good performance and good generalization.
Regarding complexity, the higher the complexity of the model, the more likely you are to have an overfitting problem and the worse it will perform out-of-sample, therefore reduce the generalization of the model.
I surely agree that cross-validation is not a tool to make a model overfit less per se, but it definitely helps to reach a better generalization by evaluating (and so allows reducing) the complexity and most likely the overfitting.
Just to clarify the terminology. We can distinguish the train and test errors/scores. Those a also referred to as empirical and generalization errors/scores. In approximated terms, a predictive model will try to minimize the empirical error and hope for the best that it happens as well on the generalization errors.
Therefore, a model that underfit does not generalize well by definition. It has just a bad score or high errors on both train and test set.
I surely agree that cross-validation is not a tool to make a model overfit less per se, but it definitely helps to reach a better generalization by evaluating (and so allows reducing) the complexity and most likely the overfitting.
Cross-validation on its own does not improve the generalization score. It informs the data scientist (or the automated algorithm) to act on the predictive model fitting to lead to a better model. So cross-validation does not act on the model, on its own, it will not improve the performance of the model. Sorry to disagree.
Therefore, a model that underfit does not generalize well by definition. It has just a bad score or high errors on both train and test set.
So we don’t have the same understanding of generalization. In my view, generalization is the ability to convey the performance from in-sample to out-of-sample. If you don’t degrade the performance on out-of-sample, you have generalization. Sometimes, a very simple (maybe a bit underfitted, i.e. not optimal) and fast model that have an average performance but can be applied on any out-of sample is preferred.
Cross-validation on its own does not improve the generalization score. It informs the data scientist (or the automated algorithm) to act on the predictive model fitting to lead to a better model.
So, informing to act for a better model doesn’t help? 
No one said that cross-validation act on the model on its own (you seem blocked on that) but cross-validation allows to reach better generalization performance since it informs us about the complexity/overfitting of the model and so we can act to improve the model! That is what I understand in the “cross-validation allows us to reach better generalization performance”.
All that may lead to confusion for those who are not familiar with the terms used here. I trust that you can improve for better clarity in the quiz questions/answers and better learning experience.
I think what you have in mind is indeed hyperparameter tuning, that is addressed in Module 3. You will then see that cross-validation by itself is not even enough to guarantee a good generalization performance. It is just one part of the process of modeling.
Hyperparameter tuning adresses complexity and complexity is related to overfitting. As I said, the higher the complexity of the model, the more likely you are to have an overfitting problem.
Let’s take the issue from a different angle.
This is the definition I understand of cross-validation (from a MIT Data Science course):
Cross-validation is a statistical technique for validating the generalization of a model when applied to independent data. This kind of validation consists of splitting the available data in various disjoint train and test subsets. Then, the model is used to form a prediction of the test data using the train data, and the performance evaluated. The goal is to validate the model’s ability to predict new data that was not part of the training set.
If a technique for validating the generalization of the model is not helpful in reaching a better generalization performance, then I have nothing left to say here.
Generalization is not only keeping the level of performance from in-samples to out-of-samples but to performing well on out-of-sample as well.
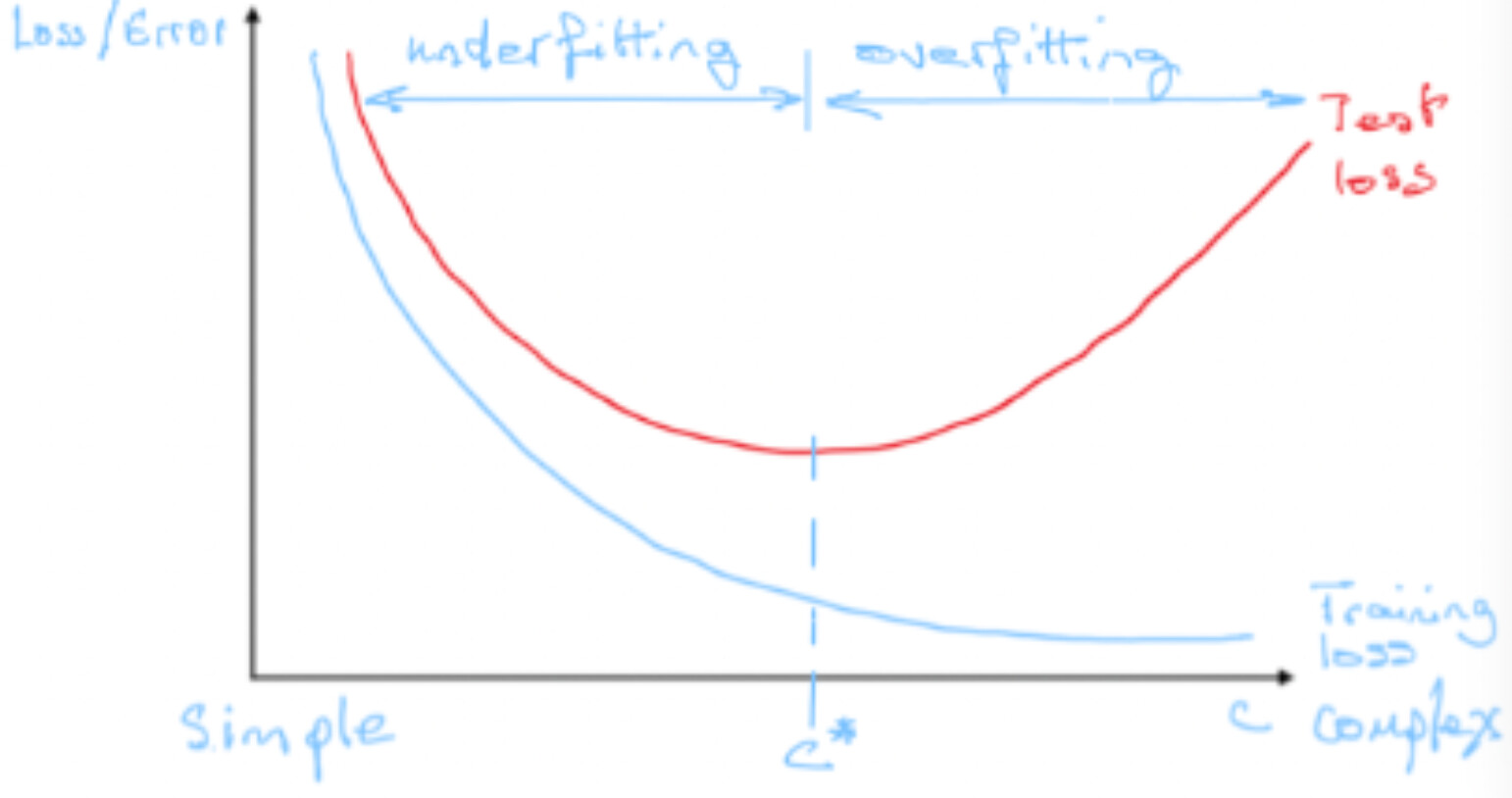
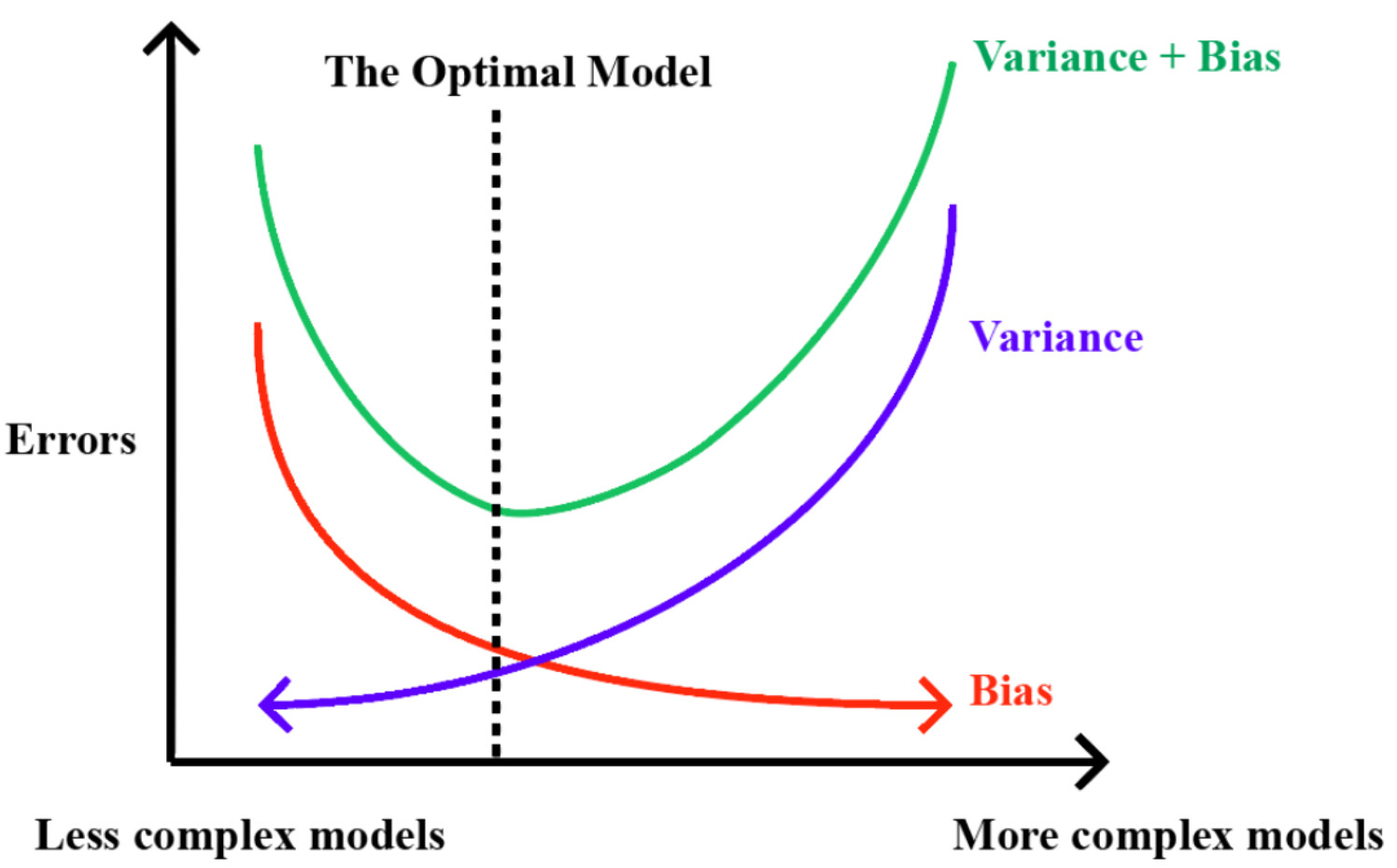
As later explained, it is a problem of bias-variance tradeoff:
The sweet spot in between those is the generalisation that one seeks when developing a predictive model.
Again, we disagree on the term generalization. We don’t expect the loss on out-of-sample be much better/lower than the loss on in-sample but similar for a good generalization. If the loss on the out-of-sample is higher than on the in-sample, then you probably have overfitting, hence bad/no generalization.
Regarding the bias-variance tradeoff, I have not yet seen the content of this
course, so I won’t comment about it.
Nevertheless, to the best of my knowledge, the bias-variance tradeoff is that we can’t reduce both bias and variance (which is the task of supervised learning) at the same time because of the noise in the training data.
So,
the expected prediction error can be decomposed as:
Now, going back to the point of this thread. One may ask two questions here:
If on both of the two above questions, the answers are “can”, then cross-validation allows us to reach better generalization performance.
Now, if you say cross-validation does not always lead to better generalization, that is true, but that’s another question.
Cross-validation alone cannot. It’s just an assessment to measure the predictive performance of a model. Hyper-parameter tuning (with cross-validation) can help improve the generalization performance in case it is bad with the default parameters (or by doing other things, like collecting more labeled data points to retrain a new model with the same parameters, removing noisy features and so on).
But ok I get your point that this quiz answer can be misleading because some readers would assume that if cross-validation reveals a generalization problem, the data scientist with use that info to improve the model one way or another. I think we should remove this option in a future version of this quiz and just explain in the solution that cross-validation in itself is just a tool to detect generalization problems but additional steps are required to improve the model if cross-validation reveals such problems.
Yes but this we did not introduce the concept of overfitting at this point in the MOOC and this is beyond the intended scope of this question.
Now, we are on the same page. I guess we initially had a semantic problem with the word “allows” in the question. 
Thank you for all the prompt feedbacks. I greatly appreciate that.