
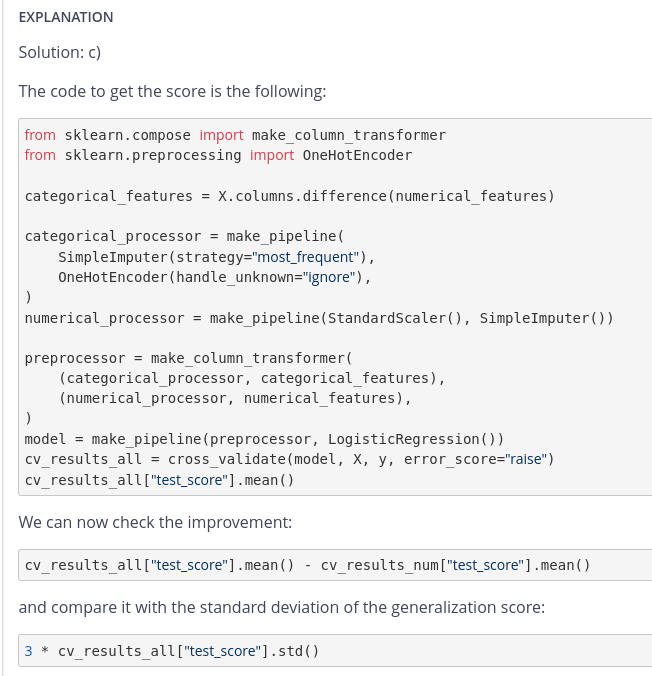
I spend lot of time to understand how to chain all transformers in a ColumnTransformer, but finally that come easy when you understand that it is possible to use a pipeline as inside a ColumnTransfomer as a nested pipeline. Maybe this notion can be help to easy answer last quiz question. Of course, maybe there are others simple methods to do that but I haven’t found 
Just a side-comment (not sure I fully understood your post) : you can compare to the solution of the wrap-up quiz which should give you some code to answer your question.
If you think we can improve something in the answer or in the previous notebook, let us know!
This is exactly the solution I found. This solution implies :
- a pipeline inside a columm_transformer
- a columm_transformer inside another pipeline
actually => a pipeline inside another pipeline : nested pipelines
This is an important concept, but I think (but may be I wrong) that this concept in not explicitly mentioned in course.
I see what you mean, hmmm in my opinion this part of the wrap-up quizz is a bit too hard, especially since this is the first module:
- contains imputation and we never talked about imputation before
- pipelines for preprocessing only and we did not mention that explicitly
I would be in favour of replacing the nans by hand with some pandas (or maybe scikit-learn if there is an easy way to do it) and have a simpler pipeline.
Or to make the improvement quicker, maybe a hint is good enough not sure …
A hint, or even make it explicitly part of the instructions to use a pipelines for each kinds of columns.