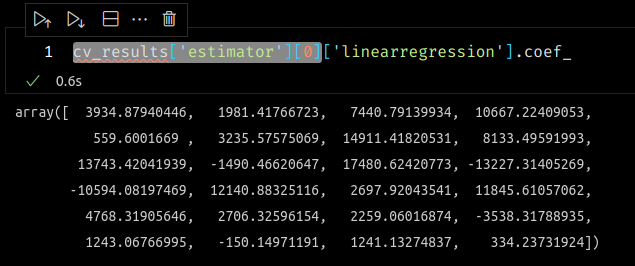
Your solution is correct but just displays the coefficients for the model trained on the first iteration of cross-validation.
Cross-validation typically train 5 to 10 (or sometimes more) models on various random splits of the data. So for each model you get a different set of coefficients.
The list comprehensions therefore return a list of 5 numpy arrays instead of one: you can check by just executing this line of the solution in a notebook cell and display the value of the coefs variable without converting it to a pandas dataframe.
Maybe also: estimator[-1].coef_ inside the list comprehension is equivalent to writing estimator["linearregression"].coef_ since estimator is a pipeline in this notebook. estimator[-1] is a way to access the last step of the pipeline, which is the LinearRegression instance in this case.