Dear All,
I promized I will make a poste on this topic : so her it is…
I am trying as an exercize to predic attrition ratio : I am basically using Kaddle attrition dataser.
Anyway : the point is this dataset is clearly imbalanced (we can expect that people resigning are less that people remaining in compagny…)
Basically whe using Tree classification I have very good results in oth train / test sets. But in fact these results are just good because model predicts only that people will not resign…
Then I used your imblearn baby with both under or over sampler. % results il lower but results becomes more realistics.
But in any case not able to make tree classification (also usng bagging, forest trees…). Still results with Ridge are slightly better.
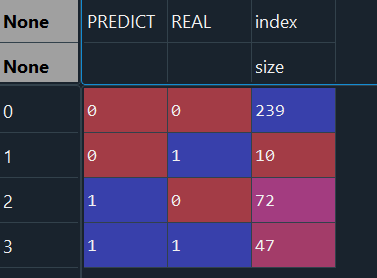
Since I already experience this imbamanced difficulty my question is : What is good strategy and better model types for such type of problem where targets ar clearly imbalanced. For info I copy here results of Ridge CV results (0 means people stay in compagny, 1 mean they will resign).
Thanks and thanks agian for this mooc content (maybe I will succeed to finish…)