
Why are inner_cv and outer_cv defined using the same random_state in KFold. Wouldn’t it result in the same folds ?
In fact if in change outer_cv to innter_cv
test_score = cross_val_score(model, data, target, cv=outer_cv, n_jobs=2)
in Nested cross-validation — Scikit-learn course
I get exactly the same results.
Here are some tests
test_score_not_nested = []
test_score_nested = []
test_score_nested_same_inner = []
test_score_nested_fixed = []
test_score_nested_best = []
test_score_nested_best_fixed = []
N_TRIALS = 20
for i in range(N_TRIALS):
inner_cv = KFold(n_splits=4, shuffle=True, random_state=i)
outer_cv = KFold(n_splits=4, shuffle=True, random_state=i)
# Non_nested parameter search and scoring
model = GridSearchCV(estimator=model_to_tune, param_grid=param_grid,
cv=inner_cv, n_jobs=2)
model.fit(data, target)
test_score_not_nested.append(model.best_score_)
# Nested CV with parameter optimization
test_score = cross_val_score(model, data, target, cv=outer_cv, n_jobs=2)
test_score_nested.append(test_score.mean())
## Custom tests ##
# Reuse inner_cv
test_score = cross_val_score(model, data, target, cv=inner_cv, n_jobs=2)
test_score_nested_same_inner.append(test_score.mean())
# Fix: Use different folds
outer_cv_fixed = KFold(n_splits=4, shuffle=True, random_state=i+N_TRIALS)
test_score = cross_val_score(model, data, target, cv=outer_cv_fixed, n_jobs=2)
test_score_nested_fixed.append(test_score.mean())
# Eval best_estimator_
test_score = cross_val_score(model.best_estimator_, data, target, cv=outer_cv, n_jobs=2)
test_score_nested_best.append(test_score.mean())
# Eval best_estimator_ with fix
test_score = cross_val_score(model.best_estimator_, data, target, cv=outer_cv_fixed, n_jobs=2)
test_score_nested_best_fixed.append(test_score.mean())
import pandas as pd
all_scores = {
"Not nested CV": test_score_not_nested,
"Nested CV": test_score_nested,
"Nested CV - inner = outer": test_score_nested_same_inner,
"Nested CV - fixed": test_score_nested_fixed,
"Nested CV - best_estimator": test_score_nested_best,
"Nested CV - best_estimator & fixed": test_score_nested_best_fixed,
}
all_scores = pd.DataFrame(all_scores)
Here is what I get.
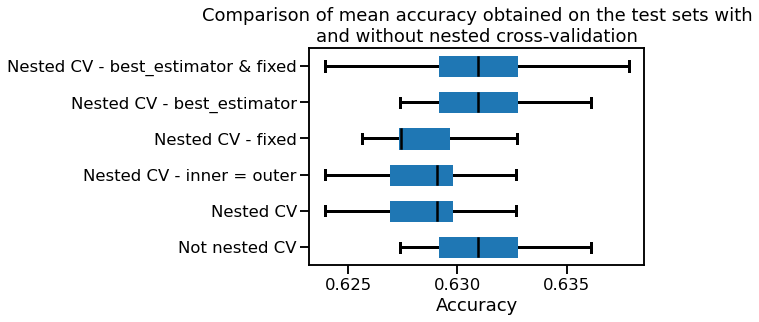
I are another question why the results on cross_val_score on the model not equal to on model.best_estimator_ but worse ?
No because, the input data will be different. The outer CV will be given the entire dataset while the inner CV will be given the training set provided by the outer CV. Since the inputs are different, the data sampled will be different as well even with the same random state.