
Bonjour,
Pourriez-vous m’aider à charger les données s’il vous plaît ? En effet, lorsque je voulais charger les données “penguins”, j’ai le message d’erreur suivant :
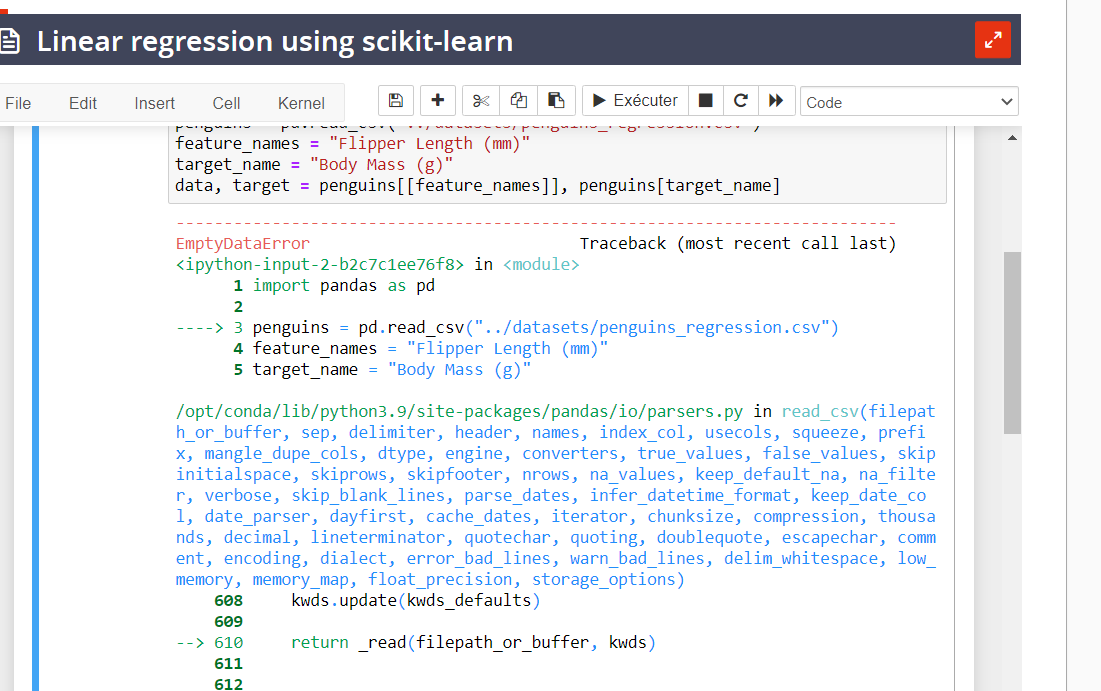
---------------------------------------------------------------------------
EmptyDataError Traceback (most recent call last)
<ipython-input-2-b2c7c1ee76f8> in <module>
1 import pandas as pd
2
----> 3 penguins = pd.read_csv("../datasets/penguins_regression.csv")
4 feature_names = "Flipper Length (mm)"
5 target_name = "Body Mass (g)"
/opt/conda/lib/python3.9/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
608 kwds.update(kwds_defaults)
609
--> 610 return _read(filepath_or_buffer, kwds)
611
612
/opt/conda/lib/python3.9/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
460
461 # Create the parser.
--> 462 parser = TextFileReader(filepath_or_buffer, **kwds)
463
464 if chunksize or iterator:
/opt/conda/lib/python3.9/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
817 self.options["has_index_names"] = kwds["has_index_names"]
818
--> 819 self._engine = self._make_engine(self.engine)
820
821 def close(self):
/opt/conda/lib/python3.9/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1048 )
1049 # error: Too many arguments for "ParserBase"
-> 1050 return mapping[engine](self.f, **self.options) # type: ignore[call-arg]
1051
1052 def _failover_to_python(self):
/opt/conda/lib/python3.9/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
1896
1897 try:
-> 1898 self._reader = parsers.TextReader(self.handles.handle, **kwds)
1899 except Exception:
1900 self.handles.close()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
EmptyDataError: No columns to parse from file
Que faire ?
Merci beaucoup pour votre aide.
lihp
 )
)