
Hi everyone,
I’m wondering the difference beetween the use of KFold(shuffle=True) and ShuffleSplit() to shuffle the data.
I did try to replace KFold(shuffle=True) by ShuffleSplit() in the exercice M6.05 and I obtained the same parameters but with better R2 scores with the latter.
after Kfold :
mean R2 score = 0.839 +/- 0.006
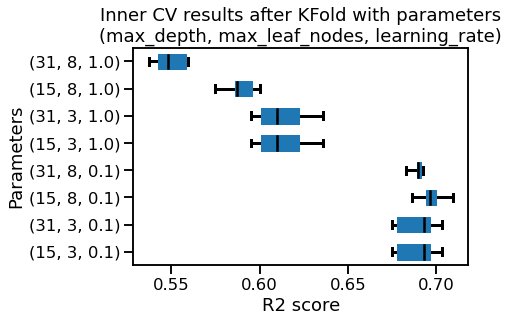
after ShuffleSplit(n_splits =5 , random_state=0):
mean R2 score = 0.850 +/- 0.009
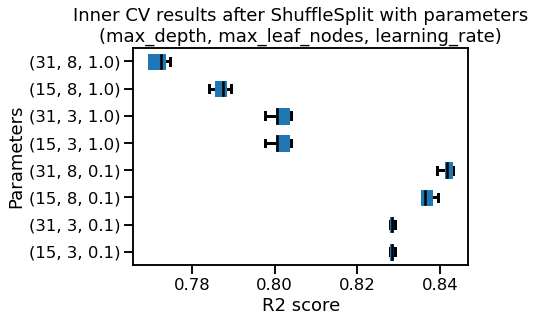
after ShuffleSplit(n_splits =5 , test_size=.25, random_state=0):
mean R2 score = 0.844 +/- 0.007
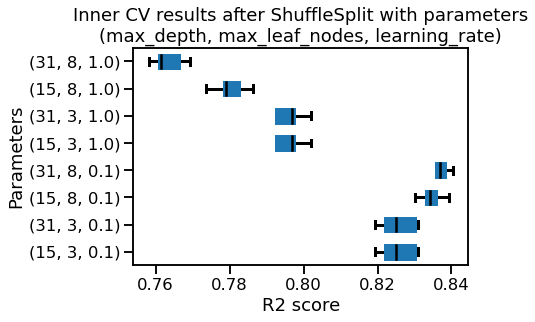
So what is the difference beetween both and could we use ShuffleSplit() here?
 ). At the end of the grid-search, we refit the
). At the end of the grid-search, we refit the 