
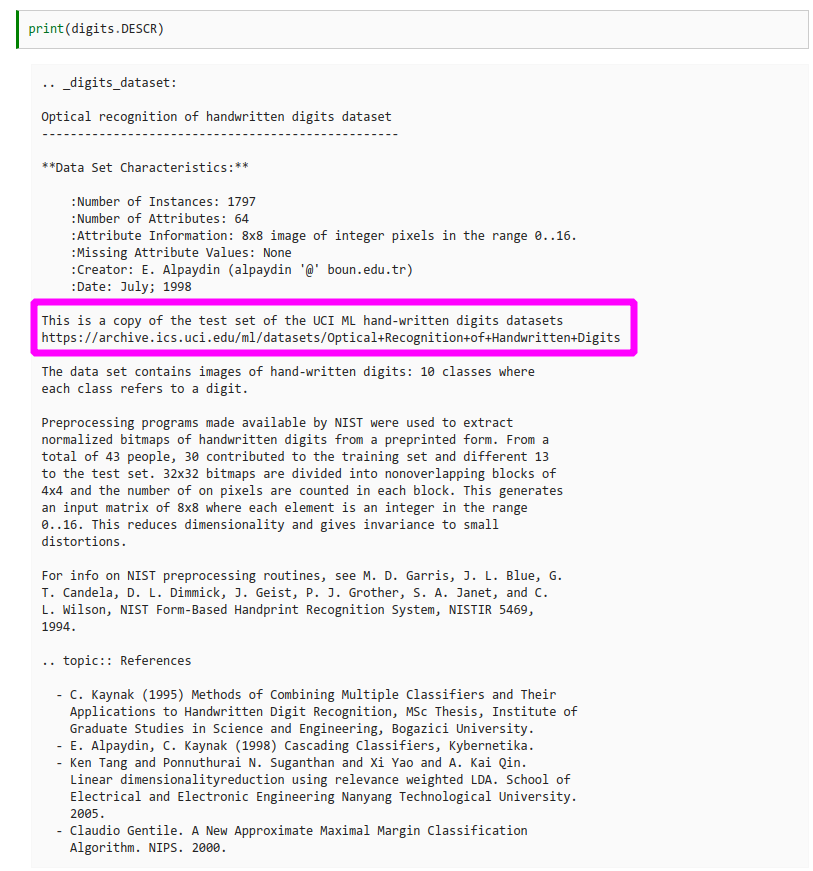
Dear all,
I find the explanation below the print(digits.DESCR) cell a bit confusing. It is stated ‘If we read carefully, 13 witers wrote the digits of our dataset…’ but actually, 43 writers wrote the digits (30 wrote the training set digits and 13 different wrote the test set). Maybe rephrase this into ‘if we read carefully, 13 writers wrote the digits in the test set, while 30 different writers wrote the digits in the training set’. Thank you for your great work and best wishes,
Pia
 If you look at the series of digits in
If you look at the series of digits in