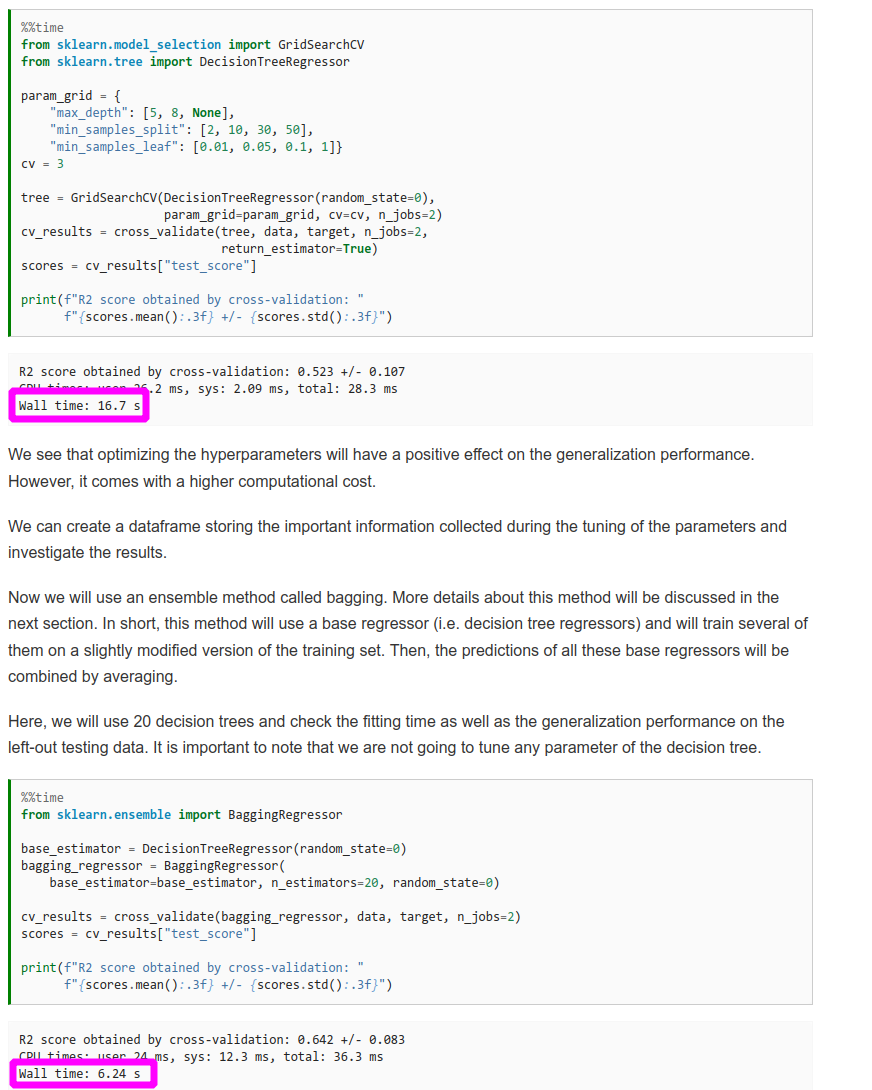
in the “Introductory example to ensemble models” little exercice you say that with BaggingRegressor :
the computational cost is reduced in comparison of seeking for the optimal hyperparameters.
But on the server it’s not obvious :
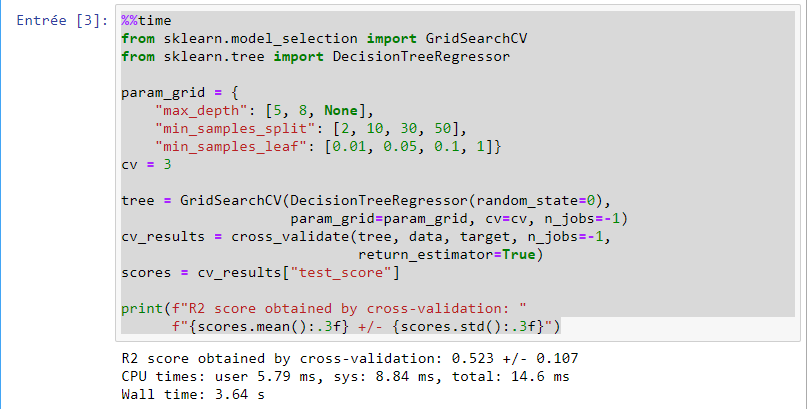
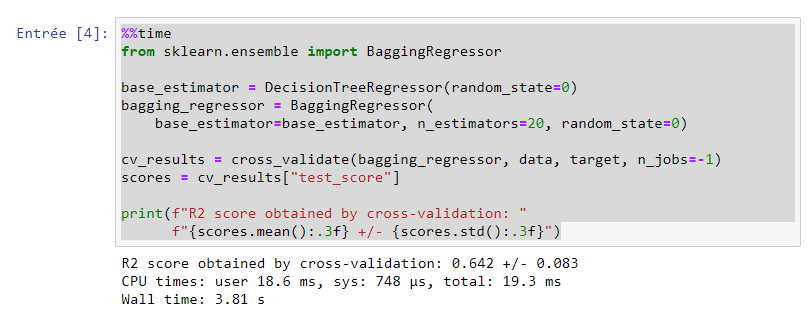
as you can see on your server cpu time and wall time is a little worse for BaggingRegressor
But if I do it locally on a linux kernel (ubuntu under WSL2):
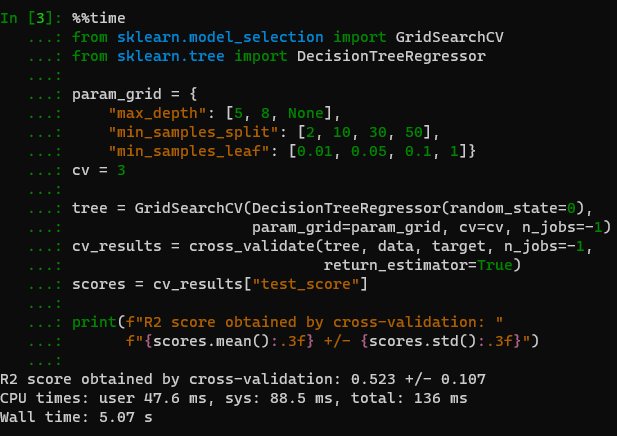
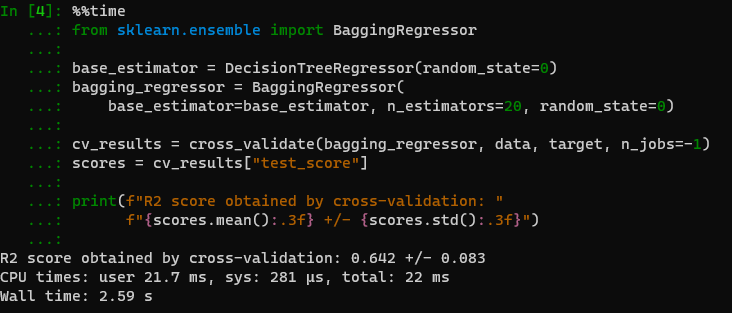
So locally you have a 6 times improvement of CPU times and a 2 time improvement of wall time.
P.S. : I was obliged to used Linux since %%time does not give CPU times on Windows