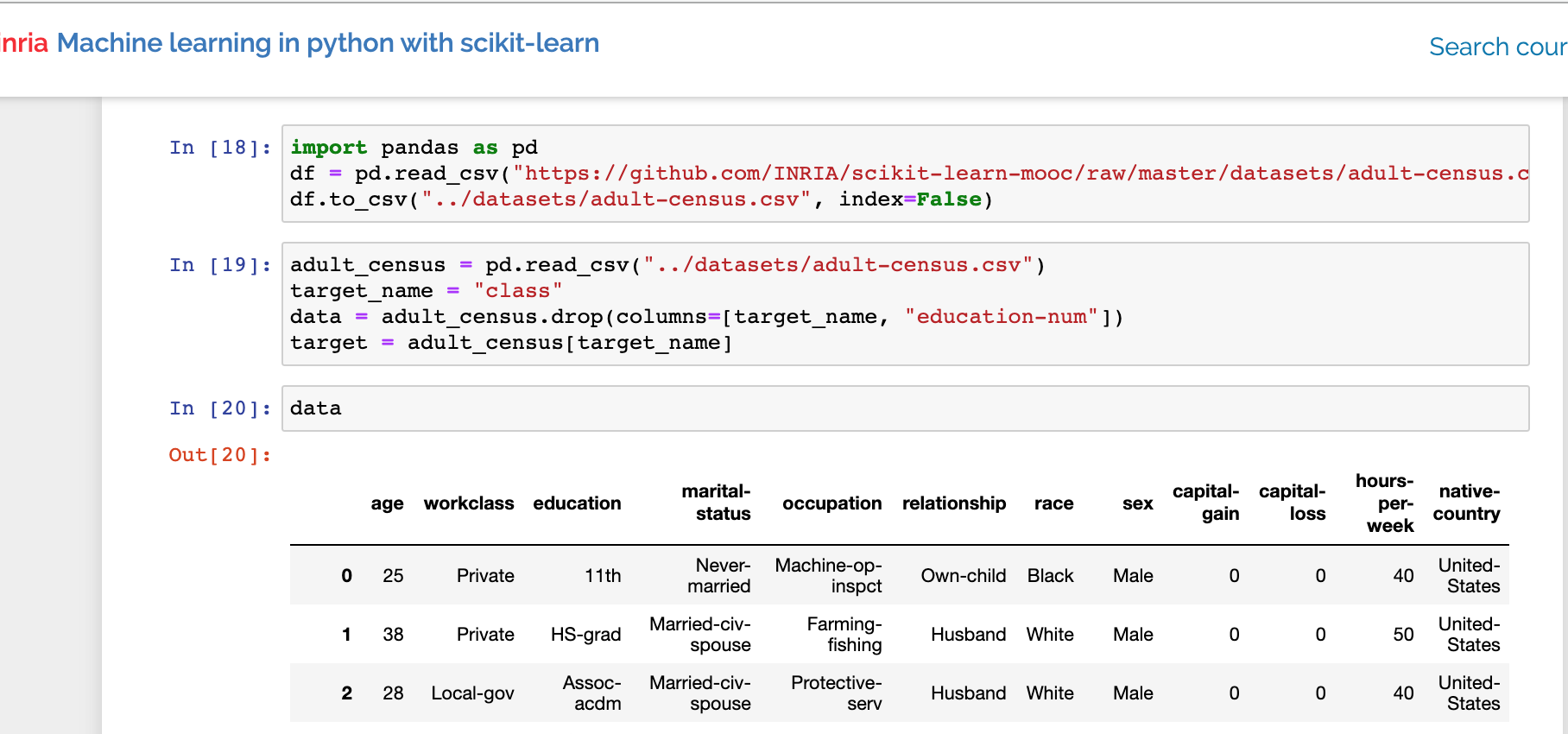
Is this comment correct? Categorical features in adult census dataset?
The adult census contains some categorical data and we encode the categorical features using an
OrdinalEncodersince tree-based models can work very efficiently with such a naive representation of categorical variables.
Since there are rare categories in this dataset we need to specifically encode unknown categories at prediction time in order to be able to use cross-validation. Otherwise some rare categories could only be present on the validation side of the cross-validation split and the
OrdinalEncoderwould raise an error when calling the itstransformmethod with the data points of the validation set.