In the wrap-up quiz 2, question 7, 8, 9, shouldn’t we convert accuracy to error by doing:
train_errors, test_errors = 1.0 - train_scores, 1.0 - test_scores
Since it is a question of error and not of accuracy.
Is it equivalent?
Thanks
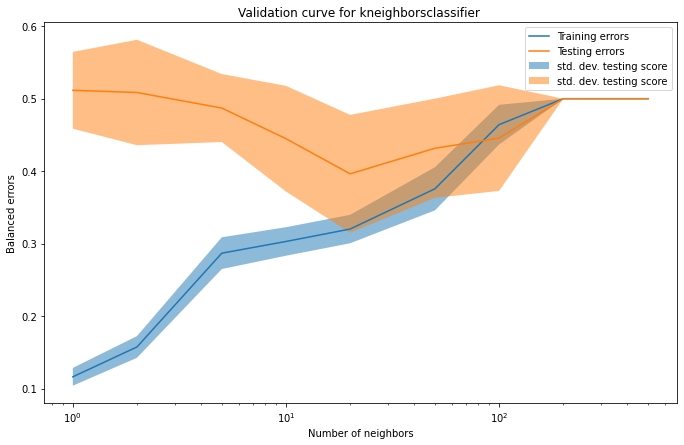

In the wrap-up quiz 2, question 7, 8, 9, shouldn’t we convert accuracy to error by doing:
train_errors, test_errors = 1.0 - train_scores, 1.0 - test_scores
Since it is a question of error and not of accuracy.
Is it equivalent?
Thanks
Usually, we will work with either score and error. The only change will be that the curved will be flipped. The analysis boils down to compare gap between curves and overall error or score. So it does not really matter until you keep in mind that a score means “greater is better” and an error means “lower is better”.
Thanks! It’s equivalent, that is what I thought. But my point is more pedagogical, inverse things are more difficult to understand, like using double negation in a sentence. Just my two cents…
Why Sklearn team did not chose to use “lower is better” to mean_absolute_error rather that the pretty convoluted neg_mean_absolute_error for regression model evaluation?
I know, consistency and understandability are sometimes difficult to well matched.
If you choose lower is better then you need to negate the score function  I would think that most metrics in classification are scores while in regression, we are more used to errors.
I would think that most metrics in classification are scores while in regression, we are more used to errors.
They are just API design. At this time, I think that the choice of using Python function was made because it would be simpler than passing an object. If it was nowadays, it seems that a Python class that could have a state greater_is_better = False/True and then having the cross_validate behind smart enough to negate internally might be more user friendly.
And they are thing that might change over year trying to improve user experience.
You’ve just proved my point.
Ok, minimizing MSE is equivalent to maximizing negative-MSE
score => higher the better
error => lower the better
But mean_absolute_error should be an error but from your answer I guess it’s a score?
Pretty messy and confusing!!! Doesn’t it?
En français, cela s’appelle nommer un chat un chat
So I have another question.
Why not always consider error as much for classification as for regression?
Would it be more consistent and understandable?
People are using accuracy, precision, recall, sensitivity, and specificity that are measures derived from the confusion matrix. It does not make sense to express the confusion matrix as “# samples - # samples in the category (FP/FN/TP/TF)”.
Indeed, there are many different metrics, (there are over 20 measures of accuracy in Sklearn for classification only). Are those all necessary? I’m pretty sure that many can be transformed in a way that all follow the rule « lower the better» or «the higher the better» and respecting that an error is an error not an accuracy score.
Sklearn team did a awesome work to simplify the pretraining and training APIs. maybe, it should be time to put more order and simplicity in the metrics mess.
No there is only a single one: the accuracy score. Other metrics are not a formulation of “the accuracy”.
Other metrics were defined first in research because they were going around limitations of the accuracy formulation for some specific problems. These metrics provide other insights regarding the statistical performance of a model and depend as well on the problem treated. You will get an overview of these metrics in the last module of this MOOC.
So you are proposing to transform any score into an error. Practically, it will be equivalent to transforming every error to a score. The statistical/ML community used these scores for ages and getting an error will not be intuitive at all.
The project is open source and thus open to proposal
Thanks for your detailed answer. Maybe we have to live with well-established traditions. 