Regularization of linear regression model
I am new to Python environment / libraries, and I take the opportunity of the course to also learn the language.
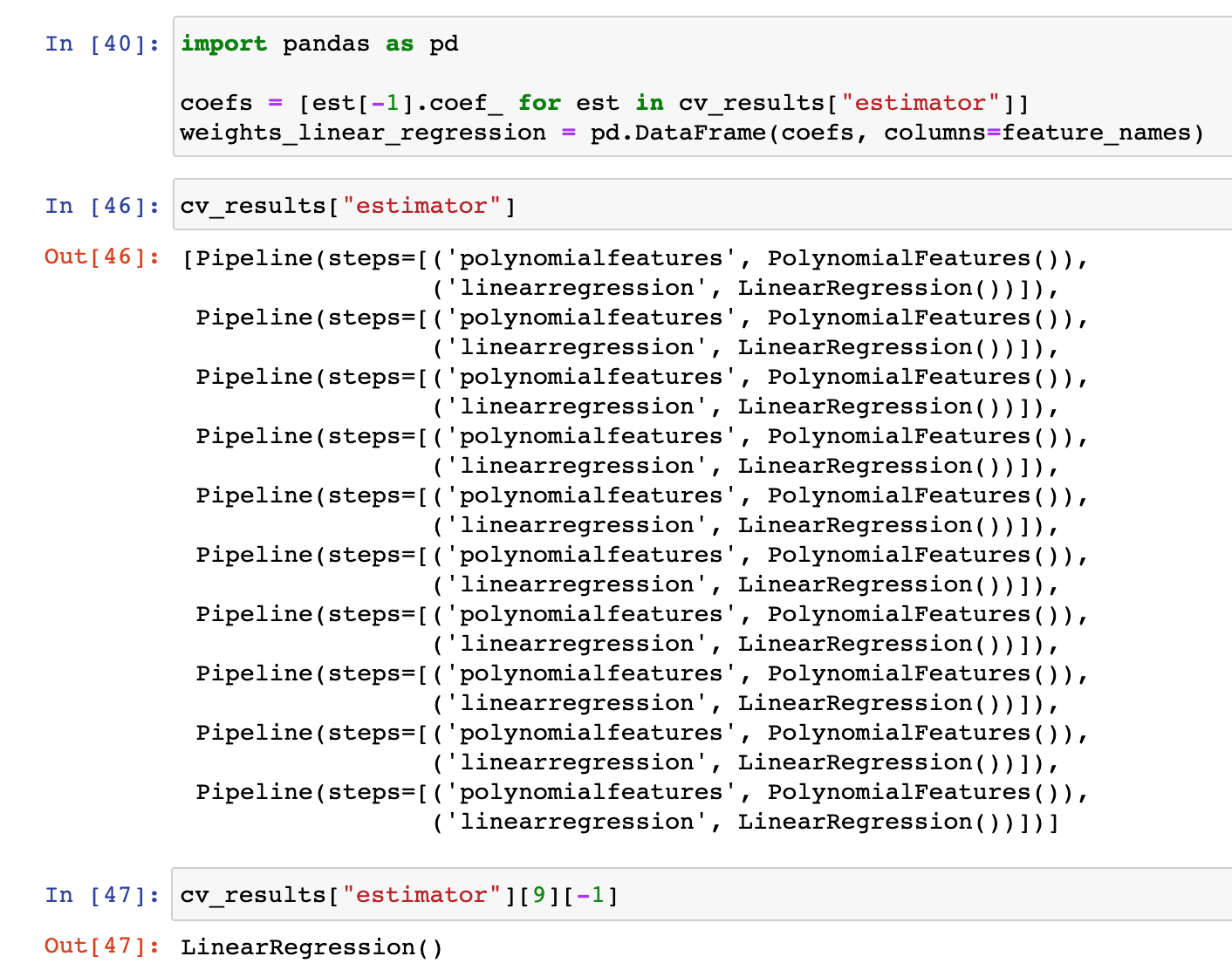
I find this line of code mysterious… What does est[-1] point to?
coefs = [est[-1].coef_ for est in cv_results[“estimator”]]
I try to break it down in pieces to “peel off the onion” but to no avail… I’m likely spending too much time on such details but I might as well dig a bit deeper.
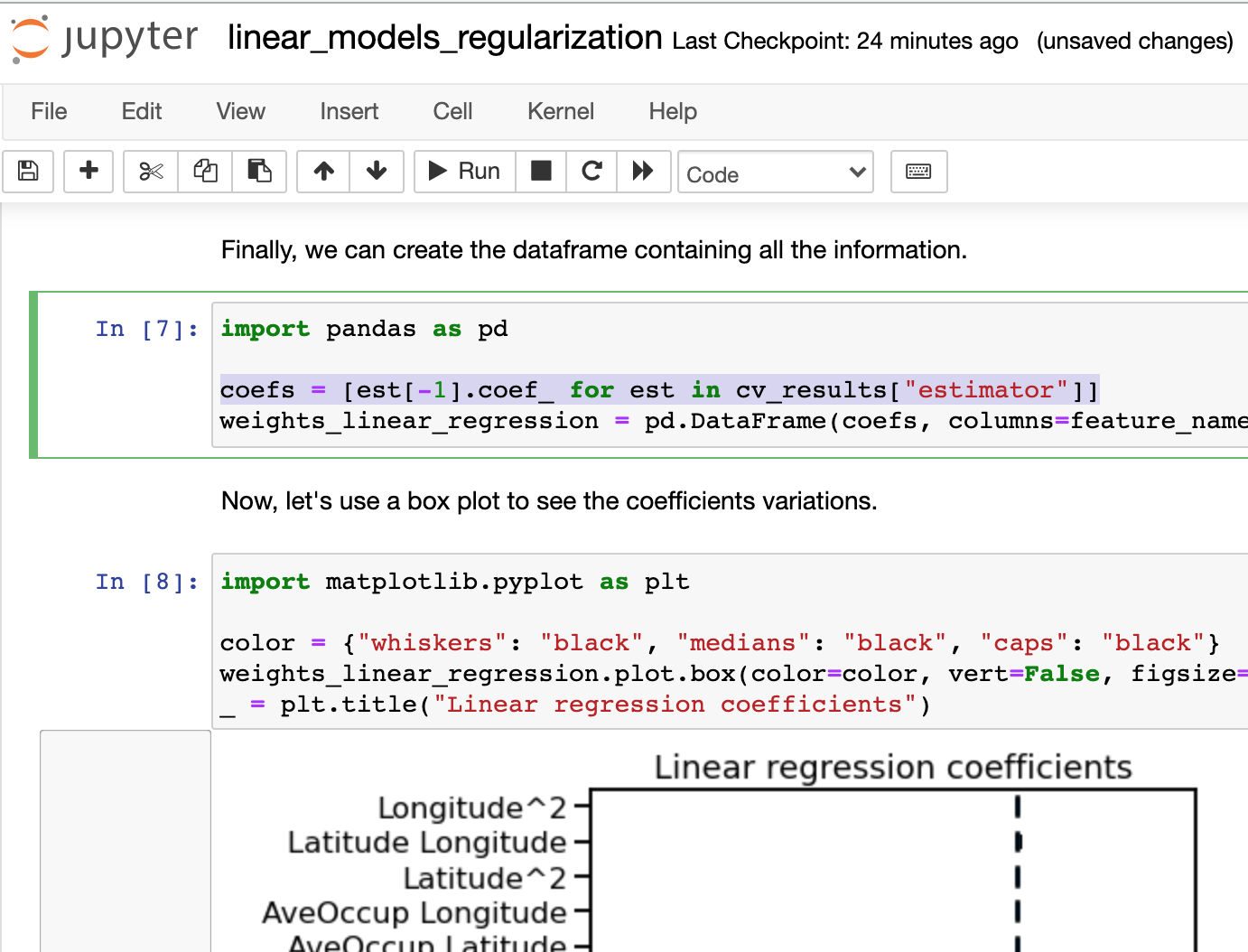
cv_results[“estimator”]