
I did quick time performance analysis based on data from Module 2 wrap-up quiz and it shows that doing KNN fit on scaled data is 2x faster than on non-scaled data. Theory quiz says data scaling doesn’t affect time performance. I wonder how should i interpret the %timeit restuls? Thank you!

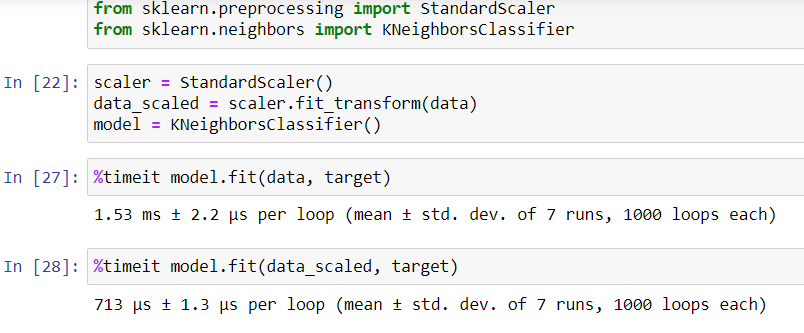
I think that what you observe is due to the small sample size. Indeed, when you do a benchmark something like this, you should make sure that mode.fit takes at least 100 ms. Otherwise, the fluctuation could come from other Python overheads that are not related to the scaling nor the fitting of the model.
I am running a similar benchmark where I make sure to have big enough dataset:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
n_samples, n_features, n_classes = 100_000, 10, 2
X = np.random.randn(n_samples, n_features)
y = np.random.randint(0, n_classes, size=n_samples)
Fitting without scaling:
%%timeit
model = KNeighborsClassifier()
model.fit(X, y)
119 ms ± 180 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Fitting with scale data:
%%timeit
model = make_pipeline(StandardScaler(), KNeighborsClassifier())
model.fit(X, y)
139 ms ± 142 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
So this is slightly slower. This little slow down should be the computational cost to scale the data.
1 Like
Thank you for this clarification.
I have separated the scaling and fitting parts on larger data set (from your code) and now these two take the same amount of time.

1 Like
Profiling performance is straightforward 
1 Like