Hi,
I’m a bit puzzled by th the solution of the Q6 of the wrapup quizz. You say :
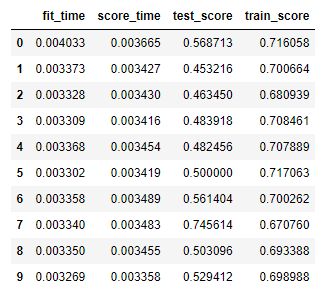
We see that the gap between train and test scores is large. In addition, the average score of on the training sets is good while the average scores on the testing sets is really bad. They are the signs of a overfitting model.
and that are the results I obtained :

So I’m wondering what is your definition for a large gap. As you can see the difference is about 0.17. In your mind what is a small or a large difference?
In the same idea what is a good score for a training set? If like here my model still do mistake on 30% of my training set do I have to consider it’s a good score??
And if my model is only about 70% accurate on my training set can I really consider than 53% is really bad for the test set??
Sorry but I have problem with subjective metrics as small/large or good/bad when they are no definition of them in the cases they are used.
Thank for your help.
ps : That is the code I used :
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
model = make_pipeline(StandardScaler(), KNeighborsClassifier())
model_scores = cross_validate(model, data, target, cv = 10, scoring = "balanced_accuracy", return_train_score=True)
scores = pd.DataFrame(model_scores)
print(f"mean test_scores is {scores['test_score'].mean():.3f} +/- {scores['test_score'].std():.3f}")
print(f"mean train_scores is {scores['train_score'].mean():.3f} +/- {scores['train_score'].std():.3f}")
In the details the scores I obtained are :