I am unable to understand the following line given as an answer to the question 4.
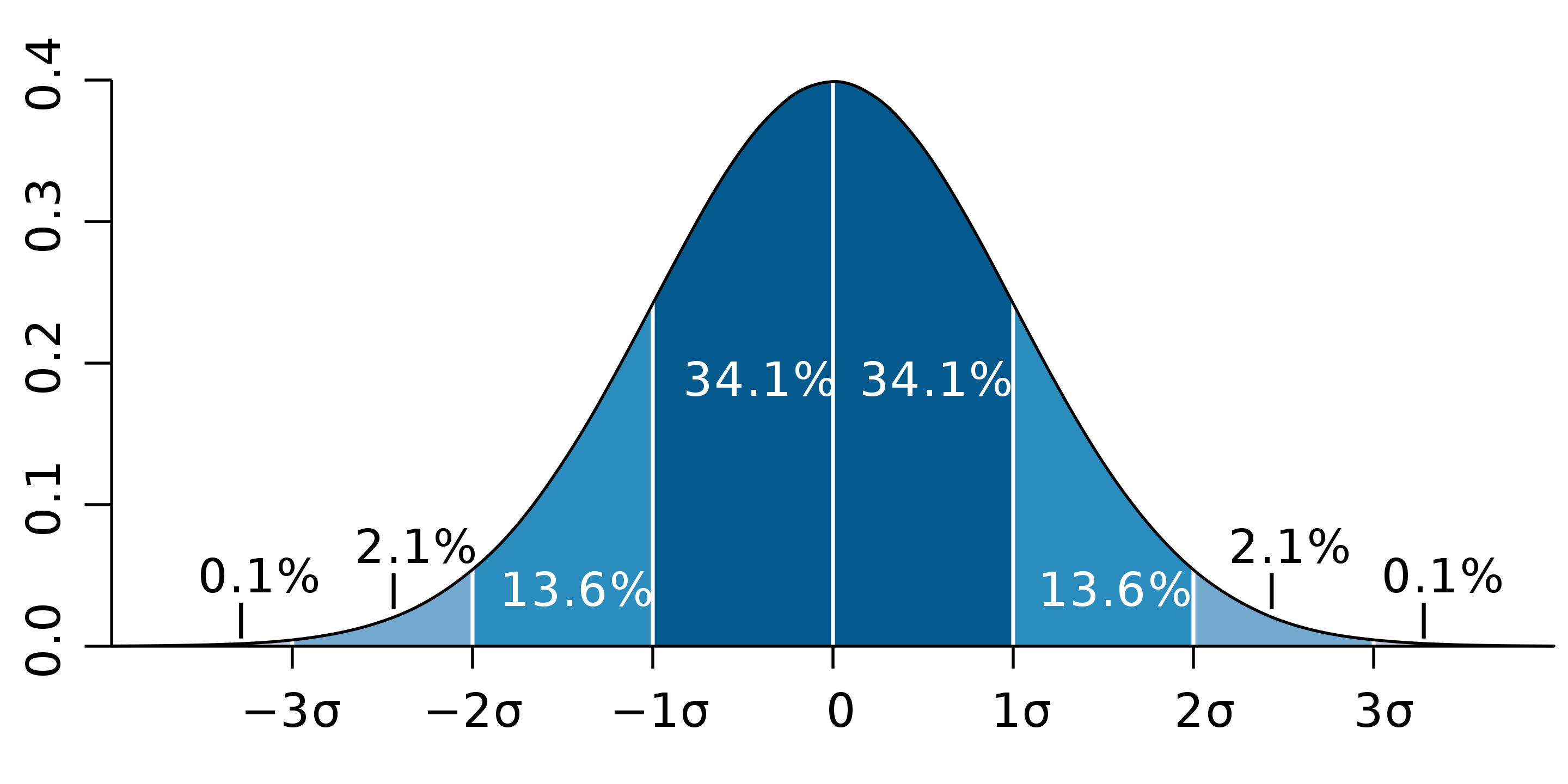
In practice, this means that each feature will have 99.7% of the samples’ values (3 standard deviation) ranging from -3 to 3 as depicted on the data transformed by preprocessing B.
How does the standard deviation is 3 ? Does the statistics tell us that 99.7% of the sample values lie in the range [-3,3] ?