Hi dear data scientists,
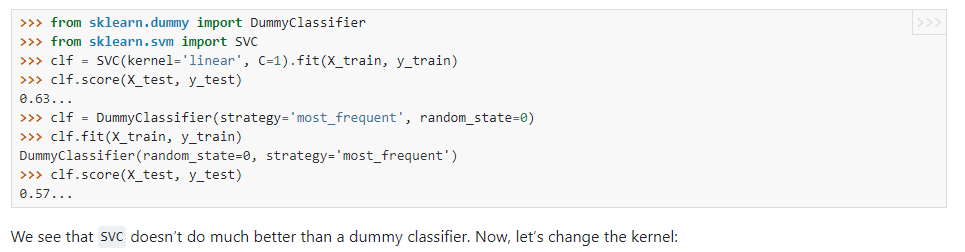
At the end of the exercice M1.03, I have obtained these results (i did the exercice before the correction of the notebook) :
Accuracy of logistic regression: 0.799
Accuracy of DummyClassifier for <=50k: 0.759
Accuracy of DummyClassifier for >50k: 0.241
What is the conclusion of these results?
Since the logistic regression model did not do much better than the DummyClassifier for the most frequent target (’ <=50k’) do we have to change the model or to refine it??
Thanks for your answers,
Sincerely,
Philippe