
Hi,
I am now confused about cross validation and the parameter cv which is also present in GridSearchCV or RandomizedSearchCV…
Question 1) cv in cross_validate
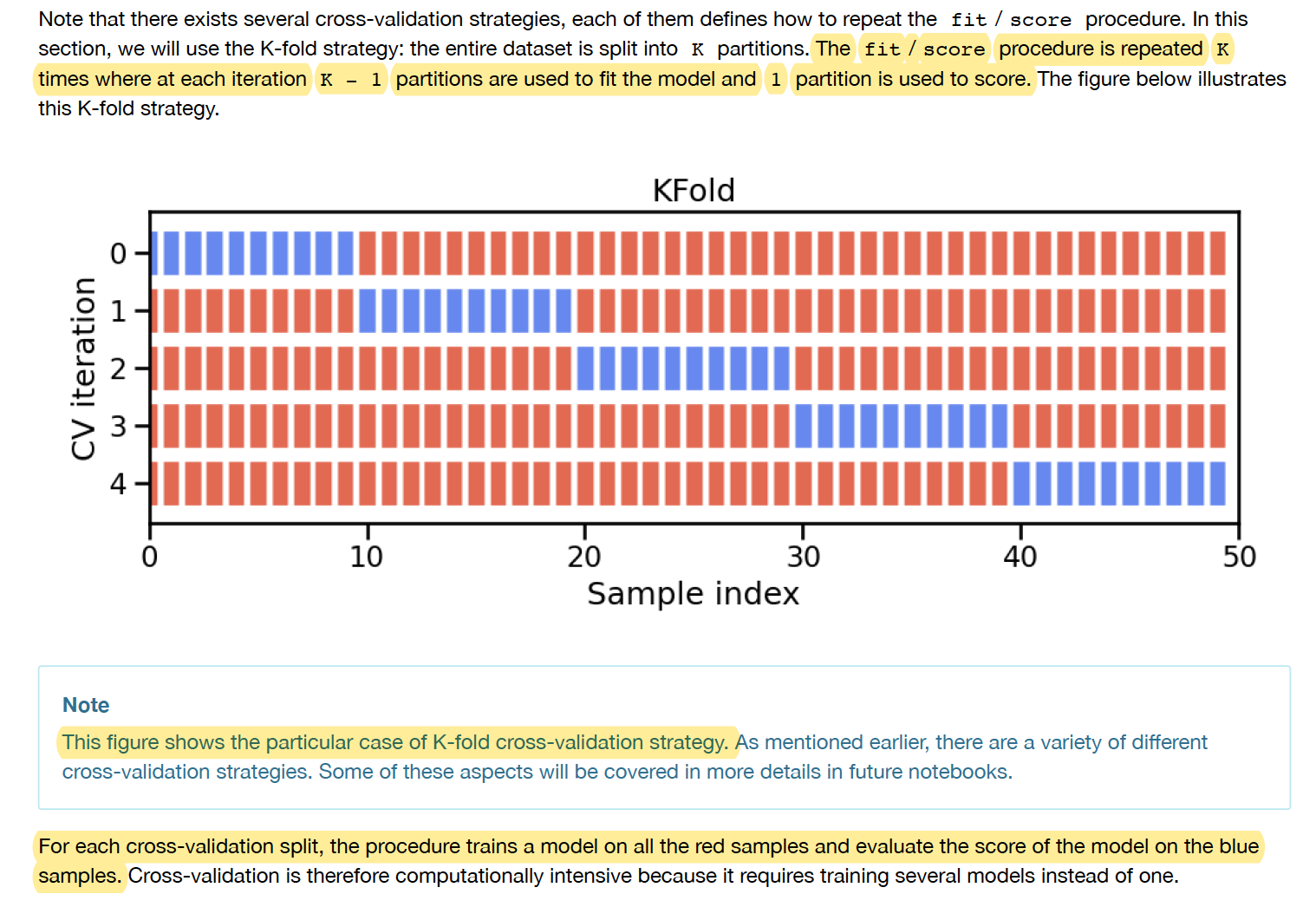
First, back to basics. In the example / picture below, can you please remind me how is the split done?
1.1) Is the entire dataset split in 5, and then validation done 5 times on each subset? cv=5?
1.2) And how is the split done between train and test on each subset?
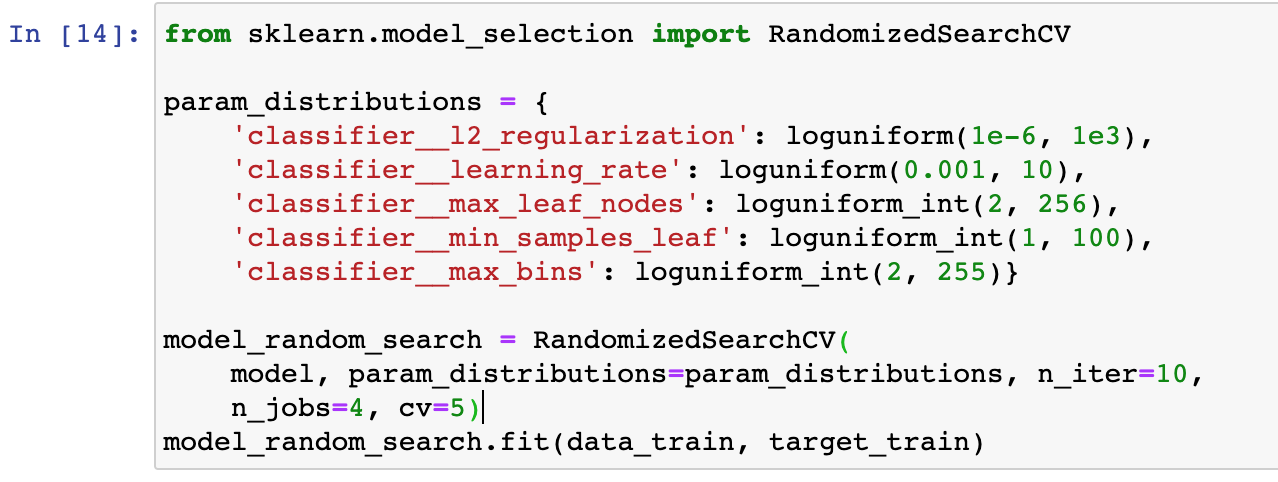
Question 2) cv in GridSearchCV and RandomizedSearchCV
When we train_test_split and then search the hyperparameter space, a cross validation also happens. Which train and test data does this validation use? The “manual” train_test_split?
Question 3) Nested cv’s
I guess question 3) could have been the last question in question 1)…
After cross_validate, we have an indication of the performance of the model (score) and a sense of the “stability” of the model with respect to its hyperparameters.
If performance is “good” and if model is stable in some region, e.g. polynomial of degree 5, we have to fit this model^5 on a train / test data after this cross validation phase, and we are happy. Is that it?
