Hello, FUN Team!
Perhaps I did not understand the question, but which answer is ultimately correct in this case?
Thanks!

Hello, FUN Team!
Perhaps I did not understand the question, but which answer is ultimately correct in this case?
Thanks!
The explanation is correct but the answer tag that we provide is incorrect. Thanks.
@lesteve @lfarhi @MarieCollin I think that we should correct since it is not only a typo. Indeed the solution is b). The explanation is correct.
@PavelKhudiakov just for completeness, I removed the screenshot from your post since it was giving away the quiz answer.
I agree explaining what the problem is without giving away the answer is a very quirky constraint 
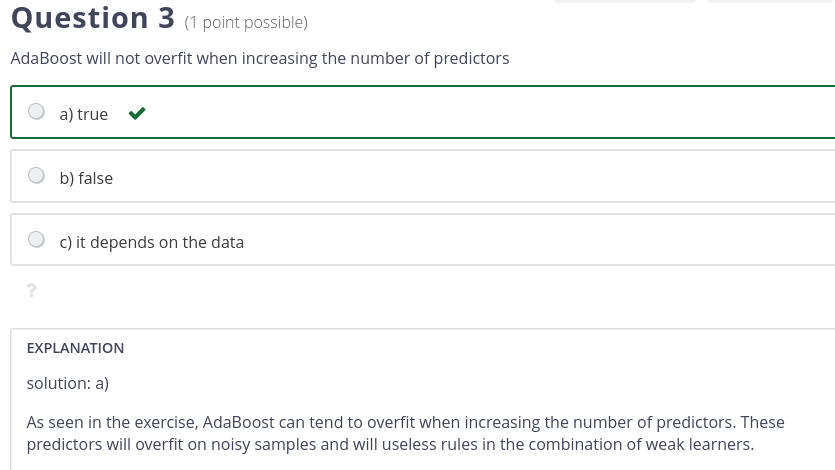
The last part of the last sentence of the explanation seems incomplete (missing verb?) or has a typo (with rather than will?):
“These predictors will overfit on noisy samples and will useless rules in the combination of weak learners.”
Am I wrong ?
The quiz is here in the gitlab.
The quiz looks like this in FUN (matches the gitlab):
So there are two (maybe three) things:
I agree with 3; it’s always better to avoid double negatives.
OK I fixed this in https://gitlab.inria.fr/learninglab/mooc-scikit-learn/mooc-scikit-learn-coordination/-/commit/906ca177c651942f583b02ccdda13c94d15c336f. This needs to be fixed in FUN.
Also we will need to reset this quiz question so that people can try it again. The answer as it was was wwrong.
No problem. I shouldn’t have posted a screenshot. But that was the only visual way to explain the problem. And of course I was planning on deleting it after your reply. But you got ahead of me. 
No worries, thanks a lot for your comment!
I think it is an acceptable pattern to post a screenshot giving away the answer and then someone from the pedagogical team edit your post to remove it.
A bit unhappy at what’s considered the right answer for this question. Doing some research, you can find links like these:
or this sequence:
Can Adaboost be overfit? - Quora
I’m not convinced with the answer considered to be the right one, given in an absolute way as it is. It seems to me it depends – on data, on settings used to train.
. 
Do you remember whether we mentioned this point in the videos/slides or other material in the MOOC? I could not find it but maybe I missed something. If this is not mentioned anywhere, I think this is not a great quiz question .
On top of this, it seems like the answer is not so simple, so this is another reason why this question is not great. We should look at this closer for the second version of the MOOC and potentially remove or improve it.
Here is an article that says that AdaBoost is robust to overfitting in a low-noise regime but will overfit in a high-noise regime: https://link.springer.com/content/pdf/10.1023/A:1007618119488.pdf.
The following is mentioned in the adaboost notebook:
“Plotting the validation curve, we can see that AdaBoost is not immune against overfitting. Indeed, there is an optimal number of estimators to be found. Adding too many estimators is detrimental for the statistical performance of the model”
The way the the question is asked is: “AdaBoost tends to overfit when increasing the number of predictors:”
Indeed this quiz question probably refers to the solution of exercise M6.03.
https://inria.github.io/scikit-learn-mooc/python_scripts/ensemble_sol_03.html
However we have another problem: the explanation in this notebook is also wrong: when increasing the number of trees in AdaBoost on this dataset (California housing), both the training and validation errors increase and the average validation error is close to the average training error, meaning that overfitting is not the main effect but underfitting is counter-intuitively increasing with the number of estimators…
I am not sure what could explain this behavior and it seems to contradict the intuitions I had about this algorithm…
Edit: interesting follow-up discussion on the scikit-learn issue tracker: AdaBoost's training error can increase with a larger number of trees · Issue #20443 · scikit-learn/scikit-learn · GitHub for those interested.
It would be great, because in AdaBoost lecture(penguin dataset) by increasing n_estimators, the classifier underfits even more, while in the Exercise M6.03 (California housing dataset) , we saw AdaBoost is not immune against overfitting. So the answer of this question seems to be wrong, plz reset it 
Hello @Meysam_Amini
The number of submissions has been reset for you for this question. You should be able to submit your answer again.
Have a nice day.
Thanks but the true answer is “it depends on data” and this question’s answer is still wrong. please correct the right answer and then reset the question state again.
Or you can change the question itself to:
AdaBoost tends to overfit when the number of predictors is not appropriate.
This issue is complex here because it requires solving a bug in scikit-learn, rework the MOOC notebooks, and correct the quiz. We will postpone this work for the next session since we are going to close the MOOC in a week.
Right now, the answer is indeed given in this topic and if it corresponds to a tiny bit of the final mark so there is no tragedy.
Its Ok thanks