if the test score calculated mathematically like that in classification model
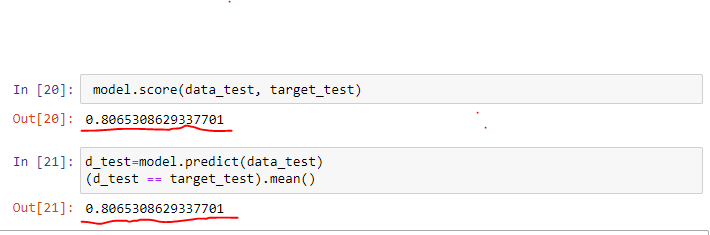
how the score or accuracy calculated mathematically in regression model in the following example ?

if the test score calculated mathematically like that in classification model
how the score or accuracy calculated mathematically in regression model in the following example ?
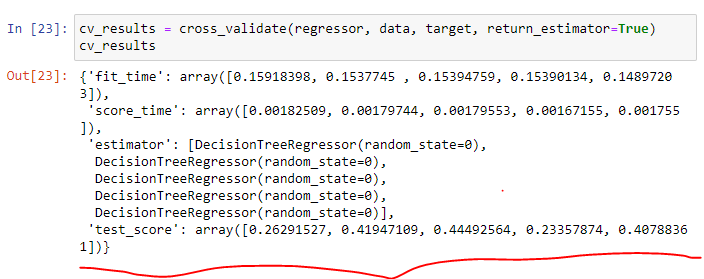
Hi, I also have a question on these five decision trees. Where is the 5 coming from?
The five decision tree regressors corresponds to the five fitted decision trees on the different folds.
Or does the fitting procedure happen to produce 5 “piecewise” decision trees?
This reported score is not the accuracy score. It is the coefficient of determination also known as r2 score: Coefficient of determination - Wikipedia
So in scikit-learn, the default score for classifier is accuracy and for regressor, it is the r2 score.
Cross-validation will repeat several time the fit/score procedure using a cross-validation procedure. By default, cross_validate will us a 5-fold cross-validation: the dataset is split into 5 disjoint partitions. The fit/score is repeated 5 times, and 1 partition is kept for the scoring while the other 4 for training.
Thus, you will obtain 5 scores.
Thanks.
cv int, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy. Possible inputs for cv are:
- None, to use the default 5-fold cross validation,
- int, to specify the number of folds in a
(Stratified)KFold,- CV splitter,
- An iterable yielding (train, test) splits as arrays of indices.
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html