
I apologize for the flurry of questions, but I think that understanding the SearchCV methods and nested CV is very important for using scikit-learn properly, so please bear with me  I promise this will be my last question for this module! Can you please confirm that this is the workflow followed by
I promise this will be my last question for this module! Can you please confirm that this is the workflow followed by GridSearchCV? I consider the default CV strategy (5-fold CV).
Given a hyperparameter grid of 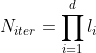 points, where d is the number of hyperparameters and
points, where d is the number of hyperparameters and ![]() is the number of levels for hyperparameter i:
is the number of levels for hyperparameter i:
- for each grid point
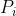 in [
in [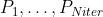 ]:
]:
- set model hyperparameters to
- for each of the 5 (
train,test) splits, fit model ontrain, compute score ontest - average the 5
test_scores - store the result in
mean_test_score[i]
- set model hyperparameters to
Finally, find the index ibest such that mean_test_score[ibest] is maximum, and refit the model on the whole dataset (unsplitted) using the corresponding hyperparameter setup ![]() . Correct?
. Correct?