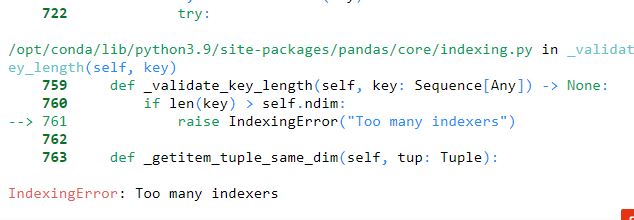
Hi,
code is not working to make a KFOLD test. Trying now for a while without finding the issue…
from sklearn.dummy import DummyClassifier
most_freq_donator_clf = DummyClassifier(strategy="most_frequent")
most_freq_donator_clf.fit(data_train, target_train)
score = most_freq_donator_clf.score(data_test, target_test)
print(f"Accuracy of a model predicting the most frequent class: {score:.3f}")
import numpy as np
from sklearn.model_selection import KFold
kf = KFold(n_splits=10)
model = DummyClassifier(strategy="most_frequent")
for train_index , test_index in kf.split(data):
data_train , data_test = data[train_index], data[test_index]
target_train , target_test = target[train_index], target[test_index]
model.fit(data_train,target_train)
pred_values = model.predict(data_test)
acc = accuracy_score(pred_values , target_test)
acc_score.append(acc)
avg_acc_score = sum(acc_score)/k
print('accuracy of each fold - {}'.format(acc_score))
print('Avg accuracy : {}'.format(avg_acc_score))