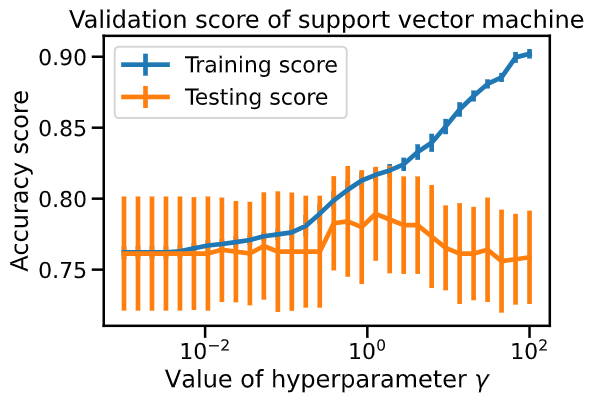
When interpreting the validation curve, it’s sayed that " while for gamma < 1 , it is not very clear if the classifier is under-fitting ". For me, since the “training accuracy” vary a little bit from 0.77 to 0.82 when gamma vary, then the model still not flexible and we can draw that the classifier is under-fitting.
Also for the learning curve, since the training accuracy and testing accuracy are approximatively constant, when adding more samples, we can deduce that the classifier is under-fitting.
Can you please confirm or decline thoses conclusions.