
Could you please check my back-of-the-envelope estimates for the computational cost of GridSearchCV and RandomizedSearchCV? Considering the default 5-fold crossval in both cases and d hyperparameters, I get:
- for
GridSearchCV: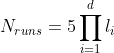 , where
, where 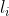 is the number of levels for hyperparameter i. In the case where
is the number of levels for hyperparameter i. In the case where 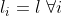 , we get
, we get 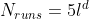 which shows clearly the curse of dimensionality here
which shows clearly the curse of dimensionality here - for
RandomizedSearchCV: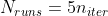 , where n_iter is the corresponding argument of
, where n_iter is the corresponding argument of RandomizedSearchCV. IIUC,RandomizedSearchCVwill try n_iter different levels for each parameter, so the exploration, at least in terms of 1D projections of the DOE, is way more thorough that withGridSearchCV. This is similar to how Latin Hypercube Designs explore the range of each parameters more thoroughly (i.e., using more levels) than Full Factorial Designs.
Is this correct? Thanks!