
the mean score is 0.11 is , out of any choice, what is wrong?
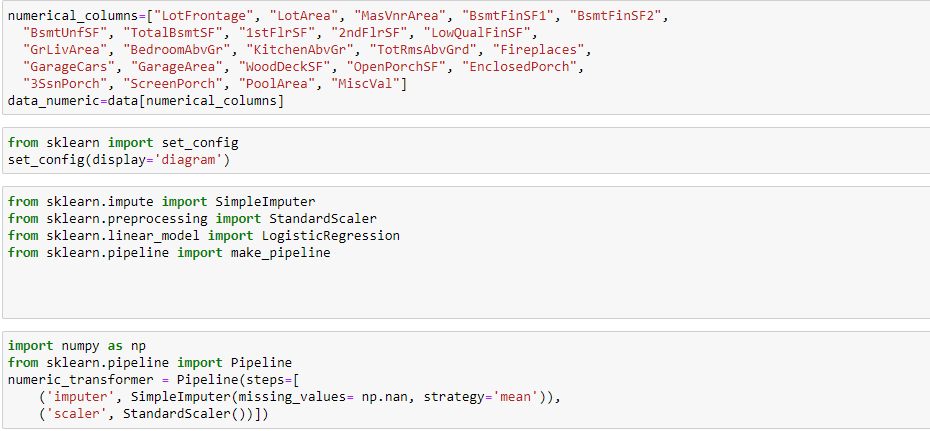
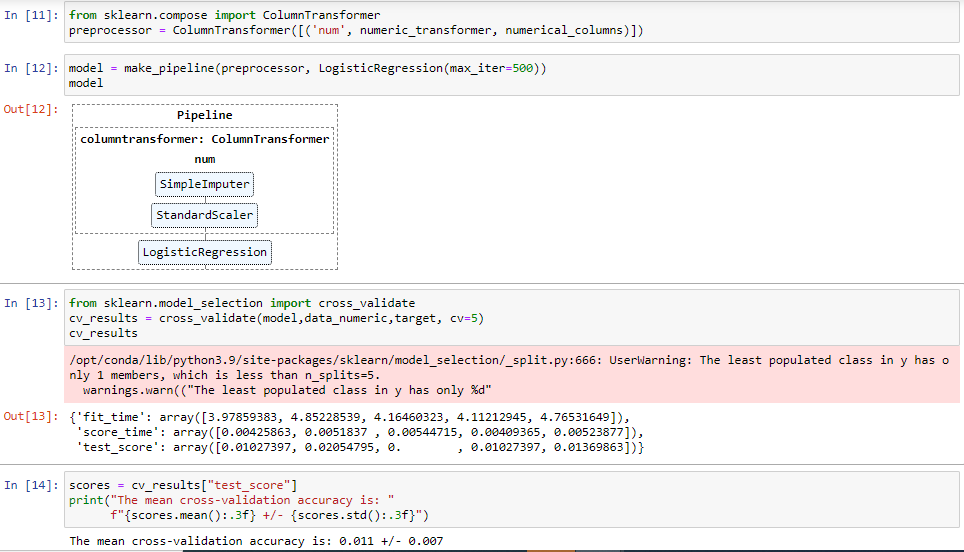
The issue is that you are using a classifier (LogisticRegression) on a regression problem (continuous target).
Switching to the right class of predictor and choosing an adequate regression metric would solve the issue (I think  )
)
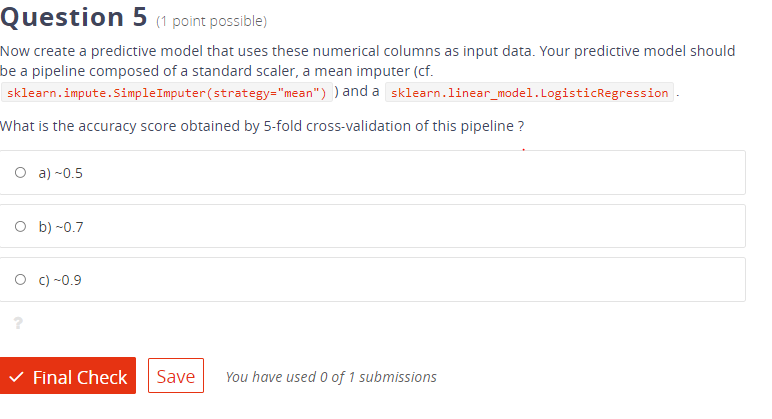
Hi, that´s right.
I tried your code and i can´t reproduce neither the error message nor the low accuracy. If i run it i get the correct accuracy score.
I would suggest you restart the notebook and run the code cell by cell again.
In addition you can simplify your model pipeline:
Your steps:
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(missing_values=np.nan, strategy='mean')),
('scaler', StandardScaler())
])
preprocessor = ColumnTransformer([('num', numeric_transformer, numerical_columns)])
model = make_pipeline(preprocessor, LogisticRegression(max_iter=500))
Mine:
model = make_pipeline(StandardScaler(),
SimpleImputer(strategy="mean"),
LogisticRegression())
The data loading and the score printing should be the same.
Right my bad, we change the original regression into a classification problem using the following line:
target = (target > 200_000).astype(int)
@AbdelrahmanMahmoud Can you check that your target was binarized in your code,
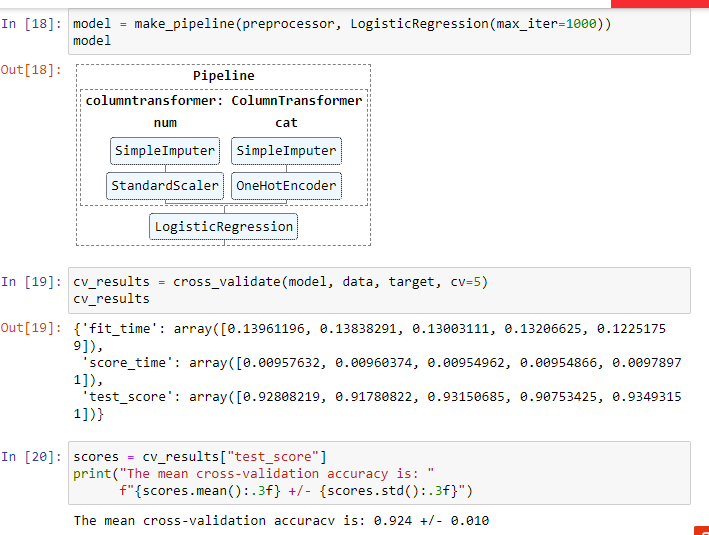

Great this explain everything 
1 Like