The instantiated model is stored in the variable model, and is now ready for use.
The third line is where the machine learning happens. We train the model using the fit method to make it fit the data:
model.fit(data, target)
This means that the algorithm is run to find the best parameters for this model. The expectation is to produce a trained model that, when presented with any line of data from the data table, answers with the matching result from the target column (in practice we won’t aim for a 100% match because that could cause issues but this is explained in detail further into the course so I won’t linger on it now).
Once the model is trained, we can use it on new data, and if everything went well, the results produced should be in line with the answers expected. Rewatch the video introduction to the course if needed, understanding those concepts is really important.
Now, for the specific case of our KNeighborsClassifier, training is pretty simple. When the fit method is called, this model simply stores the training data and the matching target values.
Then, when presented with new data, it computes the distance between this new data point and every other point in its training dataset. It then selects the 5 (or k) closest, and returns the most common occurrence among their target values.
This is a crude simplification, for more details, please refer to the Wikipedia article on the k-nearest neighbors algorithm, the diagrams should help you grasp how it works:
I am still stuck on the line
model.fit(data, target)
My understanding is, this line creates a “model” that will be used for prediction. How can I explore this entity “model”?
You can access the fitted attribute learned during fit using the dot . accessor. For instance, for a model like LogisticRegression, the documentation informed you that a coef_ attribute is created after fit. So you could access with model.coef_ if model is an instance of a LogisticRegression classifier.
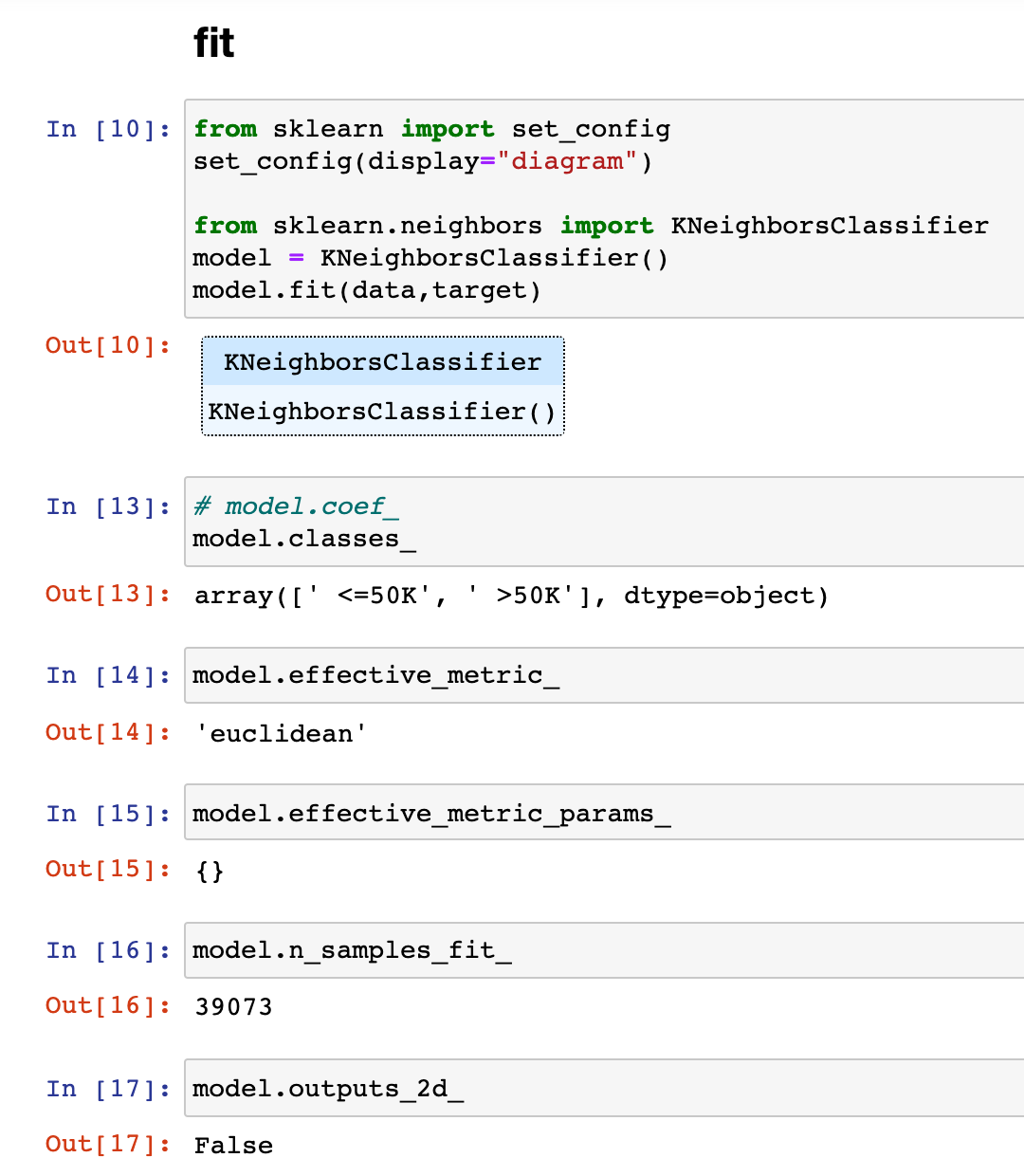
According to the documentation for knn, I don’t find an attribute “coef_” however, I found some others and used them in Sandbox (see attached image). I don’t know what value I am seeing in these outputs. Would you please tell me how I can understand and trust “model”? Thank you.
Regarding the attribute, they are documented in the documentation of scikit-learn:
Attributes
----------
classes_
Class labels known to the classifier
effective_metric_
The distance metric used. It will be same as the metric parameter or a synonym of it, e.g. ‘euclidean’ if the metric parameter set to ‘minkowski’ and p parameter set to 2.
effective_metric_params_
Additional keyword arguments for the metric function. For most metrics will be same with metric_params parameter, but may also contain the p parameter value if the effective_metric_ attribute is set to ‘minkowski’.
n_samples_fit_
Number of samples in the fitted data.
outputs_2d_
False when y’s shape is (n_samples, ) or (n_samples, 1) during fit otherwise True.
I finished Module 1, and I struggled to do that. I am asking these questions because at the beginning of Module 2 it is stated: “The required technical skills to carry on this module are skills acquired during the “The Predictive Modeling Pipeline” module with basic usage of scikit-learn.” Therefore I return to Module 1 with my questions. I begin with “Would you please tell me how I can understand and trust ‘model’?” According to Module 1, “fit” sets (creates?) “some model states” from training data and training target. Apparently these model states are all in “model.” So, what is in “model”? How did “fit” create “model.” How can I review “model” to satisfy myself it is a good output?
Aren’t those last two questions a very reasonable QC step?
Thank you.
fit create fitted attribute required for the model to predict. Each machine learning has its own model states.
In the case of a LogisticRegression, we learn a set of coefficients based on the training set; this is a parametric model.
In the case of a KNeighborsClassifier, it is indeed the full training dataset; this is a non-parametric model. Scikit-learn does not exposes publicly the training dataset as with coef_ because a user will gain little knowledge about this attribute (but this is store in model._fit_X). So when calling model.predict(X_test), we compute some distances between each row in X_test and all rows stored in this model._fit_X to find the nearest neighbors and subsequently the most occurring class label.
In a prediction setting, you will not review the model states at first. You will audit the model by evaluating the model’s predictions. This is indeed the topic of Module 2 (in detail).
Inspecting the internal of a model, for instance, the parameters if the model is parametric is sometimes done to get insights regarding why a model is giving some specific predictions. It is an advanced module and this is not covered in this first MOOC session. We will probably add such a topic in an upcoming version of the MOOC. In the meanwhile, scikit-learn provides a couple of tools to “inspect” models once fitted and we have some example to highlight those: Examples — scikit-learn 0.24.2 documentation
I think what makes it hard to understand is that the KNeighborsClassifier is a bit of a special case, there isn’t much that happens when calling fit, which can be a bit confusing.
Let’s take a linear regression as a simpler example. I assume you already encountered this method:
The idea is to model the relation between two variables as a straight line parametrized by y = a·x + b where x is the input variable, y the output one, and (a, b) a pair of coefficients to be determined.
Let’s say that you would like to predict the length of a person’s arm given only their height from head to toe. I wouldn’t be absurd to assume that those two values could be in a linear relationship.
You would start by collecting data from as many people as possible to get a sample on which to base your model. Maybe you got 100 volunteers or something, and measured both their height and arm’s length. When plotting each of those 100 samples on a scatter plot, you would get a cloud of datapoints with a clear trend: taller people have longer arms.
Our goal is to express that relationship using our linear model y = a·x + b . Where y is the arm length, and x the height. Now is the time we would enter the equivalent of our fit method, except we are doing it by hand.
<fit>
We try to find a and b so that the produced line stays as close as possible to our data points. I’ll let you follow the Wikipedia page linked at the start of the post for the exact algorithm, but the idea is to minimize the sum of squared errors. It’s not really complex, but can be time consuming to do by hand. At the end, we get values for a and b.
</fit>
That’s the end of the fit part of the process: we now have the parameters required by our model, it is ready to be used! By measuring anyone’s arm, and plugging the value as x in our equation y = a·x + b, we should get as y a pretty good estimate of the length of their arm.
But what if we were interested in the length of their feet instead? We can’t use this model: the a and b parameters we computed for arms, they wouldn’t produce a good value for feet.
Our equation y = a·x + b still looks pretty promising, though, it’s just the values of a and b that need to change. To do so, we would perform our fit operation again, this time using feet length data rather than arm length data. The model would still be a linear regression but its parameters would have changed.
fit is “training” the model by finding the best parameters that fit the data provided.
This is machine learning in the sense that the computer is computing the parameters by itself to find a model that fits the data.
Now, back to our KNeighborsClassifier model. This one is a bit special because the parameters it uses are actually the entire training dataset. So when you try to look up what it has learned, you’ll only find the training dataset, but no interesting value derived from it. This is the confusing part that makes it look like a parameterless model.
I give up. Perhaps if this course is offered again a year from now I will have gained enough understanding of sklearn to take part. On the other hand, if I have done that, I don’t need this course, right?
I made it into Module 3 and tried hard all along to understand, but I have only the barest understanding of what is going on.