I’m not one of the organizers, but I’ll try to answer anyway, errors and omissions excepted  A transform is an estimator (an object with a
A transform is an estimator (an object with a fit method), and it’s fit to a dataset as explained here. In other words, the model state (which for StandardScaler is given by the the arrays
scaler.mean_ and scaler.mean_, i.e., a mean and a scale for each column/feature of the dataset) is learned based on a dataset. This dataset is the training set, as you can see:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(data_train)
So there’s no data leakage: you learn the model state (the column means and scales) on the training set. Then, when you use predict on a test set, the means and scales are not recomputed from data, but you simply call the transform method with a fixed state, learned from the training set. For example:
model = make_pipeline(StandardScaler(), LogisticRegression())
model.fit(data_train, target_train)
predicted_target = model.predict(data_test)
As explained in the lecture, inside predict
The method transform of each transformer (here a single transformer) is called to preprocess the data. Note that there is no need to call the fit method for these transformers because we are using the internal model states computed when calling model.fit . The preprocessed data is then provided to the predictor that will output the predicted target by calling its method predict .
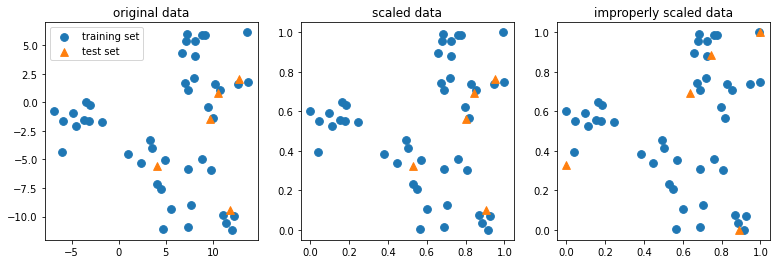
The StandardScaler internal state is thus learned on the training set, and applied in the same way to the training and the test set. So, at the same time, there’s no data leakage from train to test, and there’s no change in “the relationship between observations within a variable” (whathever that may exactly mean) because exactly the same transform is applied to all observations of a dataset. For all observations of a feature X, I subtract exactly the same mean, and divide by exactly the same scale, irrespective of whether the observation belongs to the training set or the test set.


 . In this particular case, I think your answer is very thorough!
. In this particular case, I think your answer is very thorough!