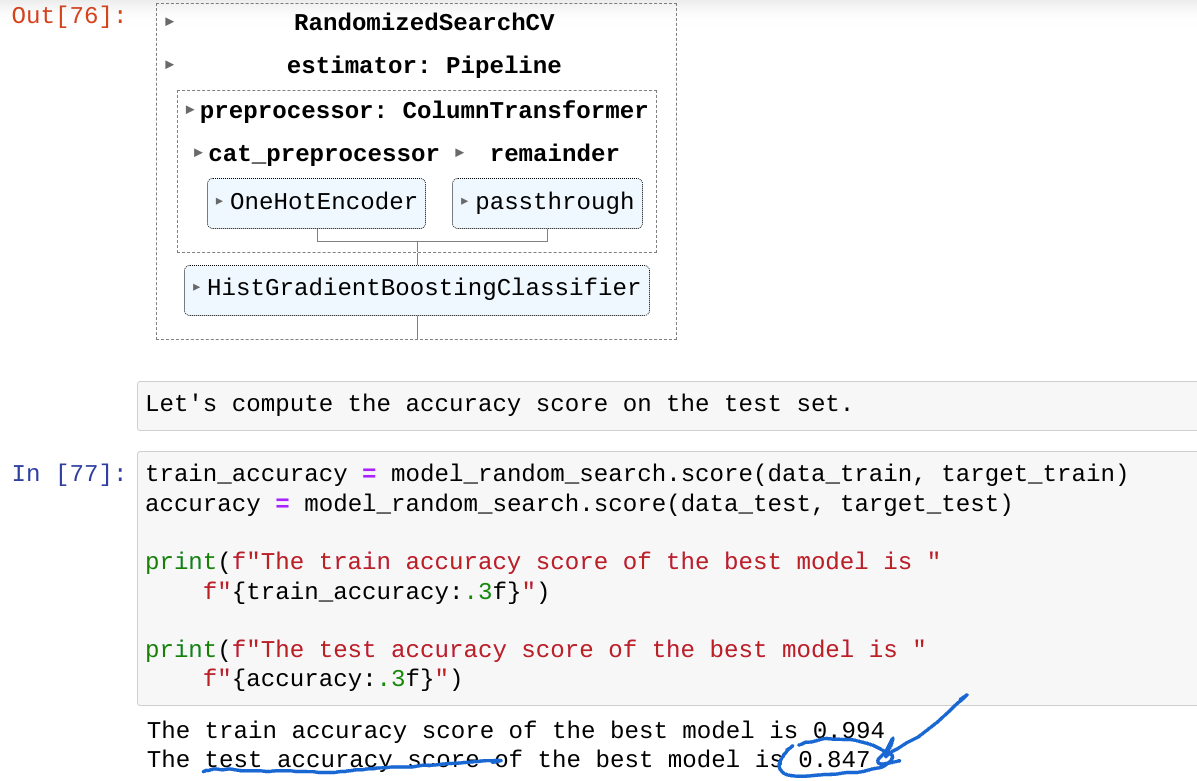
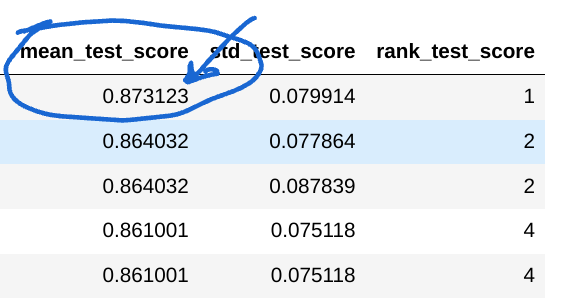
They are both accuracies but they are computed on different datasets. The latest is the output of cv_results_ which is the mean accuracy score computed by cross-validation inside the random search.
So taking the line of code allowing to obtain the result, you should have something like:
search_cv = RandomizedSearchCV(...)
search_cv.fit(X_train, y_train)
So internally, X_train is split several time and we train several models and subsequently assess them.
The mean_test_score is the average of the those scores.
The former score is the output of something like:
search_cv.fit(X_train, y_train)
search_cv.score(X_test, y_test)
It means that we perform the previous cross-validation, compute the internal mean_test_score, select the best set of parameters and finally train a single model, with the set of parameters on the entire training set X_train. We finally assess this model on a single split using the score method on X_test (there is no average because of this single split).
Hope that this explanation helps.