Hello, I have two questions :
- what are you referring to when you talk about “iterations” (at the end of this notebook),
- I totally don’t get why using scaled date will reduce the number of these iterations ?
owen77s

Hello, I have two questions :
owen77s
what are you referring to when you talk about “iterations” (at the end of this notebook),
Some algorithms such as LogisticRegression is based on an iterative solver to find the best model. For instance, gradient-based solvers are using such a strategy where at each iteration the coefficient of the model is updated based on the gradient of the loss function.
It translates in scikit-learn by having a parameter max_iter in the predictive model that used such an approach.
I totally don’t get why using scaled date will reduce the number of these iterations ?
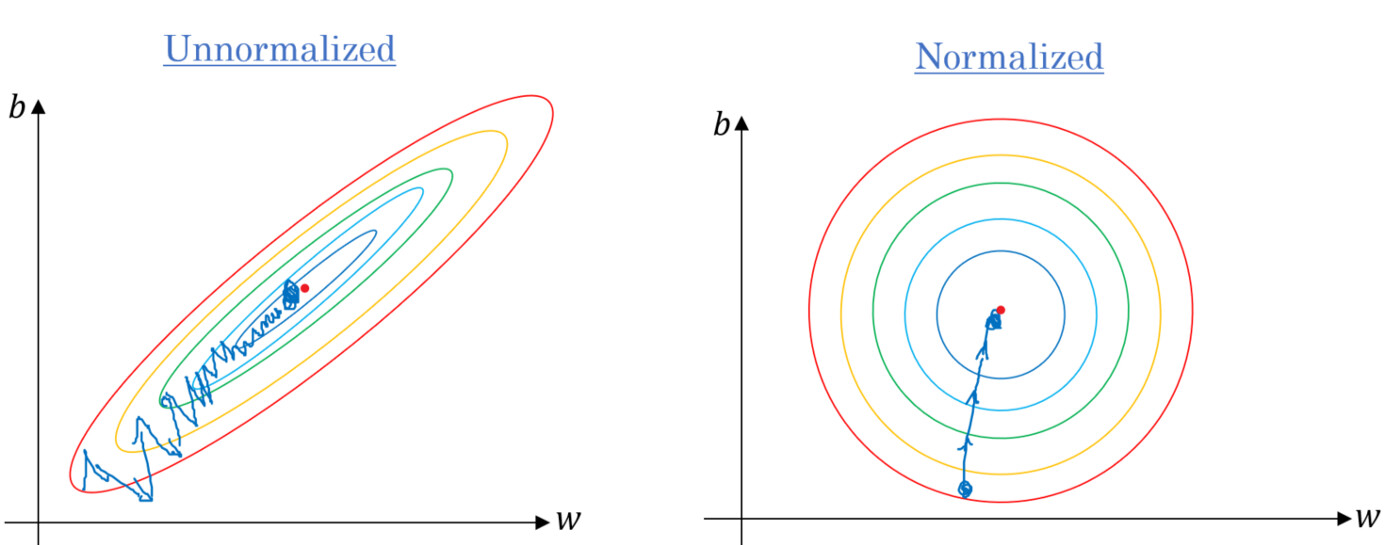
We can better understand what happens with the following figure
source: Gradient Descent Algorithm and Its Variants | by Imad Dabbura | Towards Data Science
In an unscale feature space, the loss function will look like the figure on the left. The difference in dynamic ranges of features will impact the shape of the loss function. The gradient at a particular place in the loss will be highly impacted by features with a large dynamic range in comparison with features with a lower dynamic range. Scaling will make this effect disappear as the figure on the right.
In these figures, the gradient descent corresponds to following the blue line. Since the gradient does not well behave on the left-hand side figure, the number of iterations to reach the minimum is higher than on the right-hand side figure.