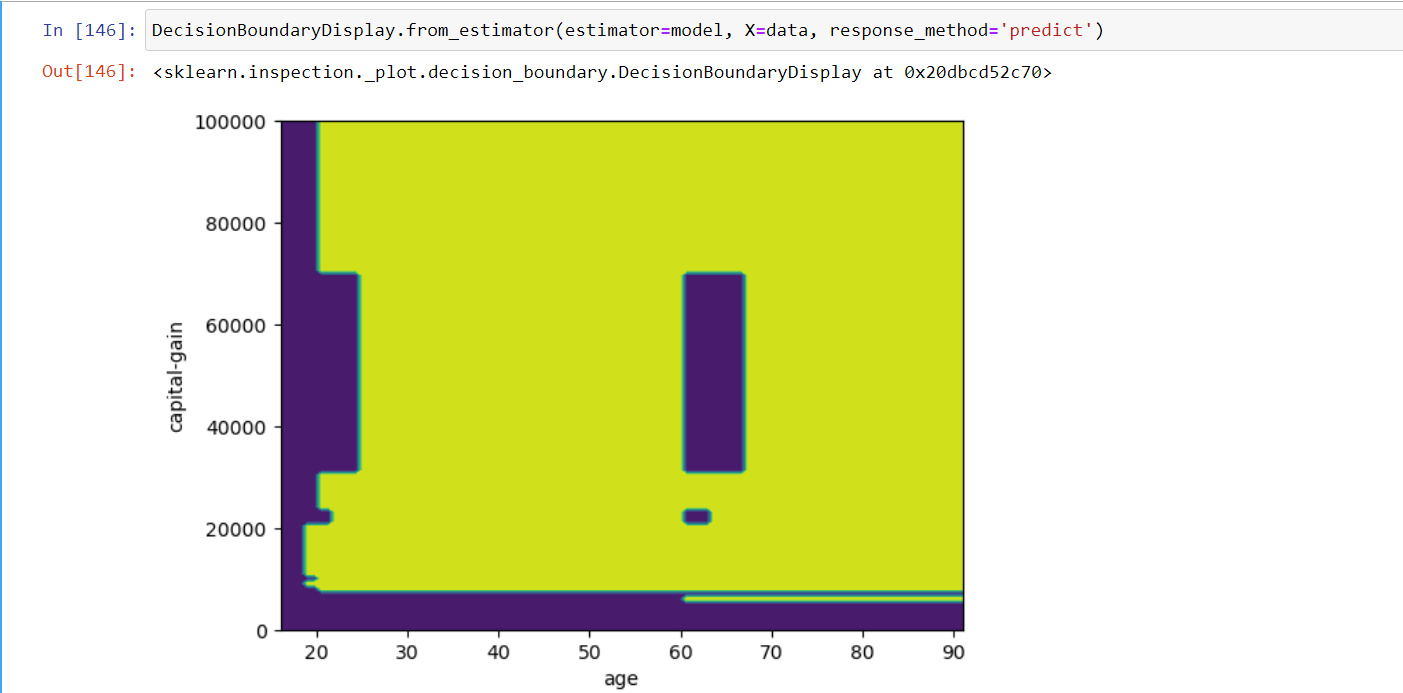
Hello everyone,
I’m stuck when displaying the Decision Boundary figure for this exercise.
Code is very simple :
adult_census = pd.read_csv("https://raw.githubusercontent.com/INRIA/scikit-learn-mooc/main/datasets/adult-census-numeric.csv")
data = adult_census.drop(columns="class")
model = KNeighborsClassifier(n_neighbors=5)
model.fit(data, target)
DecisionBoundaryDisplay.from_estimator(estimator=model, X=data, response_method='predict')
This is the error code I receive, but my data has not AT ALL any NaN value.
I even tried to use a SimpleImputer to replace 0 values by the ‘most-frequent’ value and it still does not work.
Any idea of why it does not work ?
Input X contains NaN.
KNeighborsClassifier does not accept missing values encoded as NaN natively. For supervised learning, you might want to consider sklearn.ensemble.HistGradientBoostingClassifier and Regressor which accept missing values encoded as NaNs natively. Alternatively, it is possible to preprocess the data, for instance by using an imputer transformer in a pipeline or drop samples with missing values. See https://scikit-learn.org/stable/modules/impute.html You can find a list of all estimators that handle NaN values at the following page: https://scikit-learn.org/stable/modules/impute.html#estimators-that-handle-nan-values
However, when using a HistGradBoostClassifier, the Decision Boundary displays well and return this figure.
Question : Why does the Decision Boundary displays ‘capital-gain’ & ‘age’ and not ‘capital-loss’ & ‘hours-per-week’