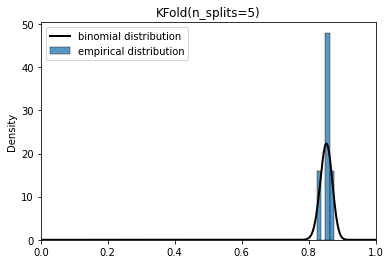
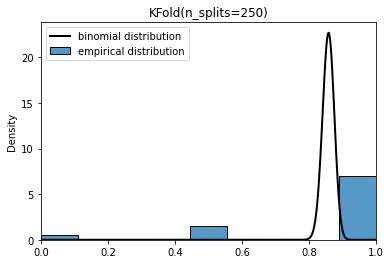
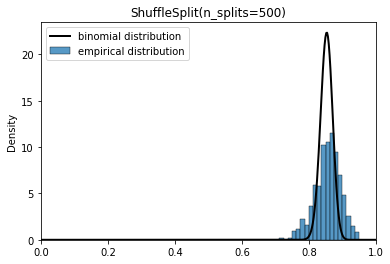
Hi, I am a bit puzzled when it comes to the differences between cross_validate(shuffle=True) and ShuffleSplit.
My understanding is that, in the case of the ShuffleSplit, we might end up using the same data-points within each split, whereas in the cross_validate(shuffle=True), this cannot happen.
In general, what is the criterion in selecting one over the other?
Thanks again for your time and this beatiful course.