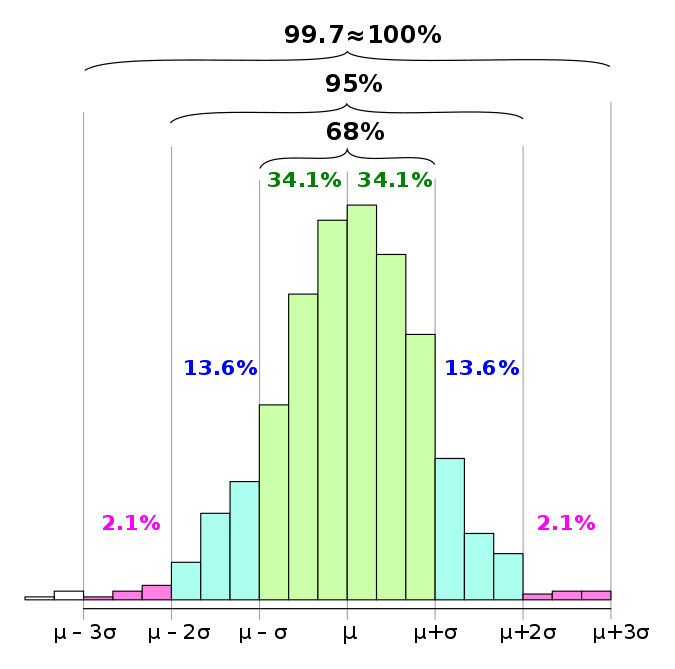
so that they have a standard deviation of 1.0 on the training set. In practice, this means that each feature will have 99.7% of the samples’ values (3 standard deviation) ranging from -3 to 3
This might be very simple, but why does the standard deviation of 1, scales the data from -3 to 3? How could we calculate that beforehand?
Thanks