
It is a bit unclear for me at this stage, what is the learning algorithm and the prediction function (e.g: in the specific case of the KNN). Is the prediction function the loss function? But isn’t a loss function necessary to the learning process?
Think of the prediction function as the function run internally when calling predict. The KNN learning algorithm does not have a loss function that can be minimized during training. In fact, this algorithm is not trained at all. Calling predict will do the function: search for the closest samples.
1 Like
Hi @ArturoAmorQ—Thanks for your reply. That covers the predict part. How about the learning algorithm of the fit part? According to the course:
The fit method is composed of two elements:
- A learning algorithm
- Model states
Thanks,
KNN is a bit of a special case. The only “training” that happens during fit is creating a local copy, so that during prediction time you can do a search and technically, no function is fitted to the data.
Regarding your original question, let me use a particular example. Consider the Ordinary Least Squares (OLS) linear regression to be our learning algorithm, then the prediction function would simply be y = mX + b.
In this case, the fit method is composed of two elements:
- A learning algorithm i.e. the minimization of the loss function, which could be the Mean squared error (MSE)
- Model states i.e. the consequential learning of the slope and intercept (
m,b)
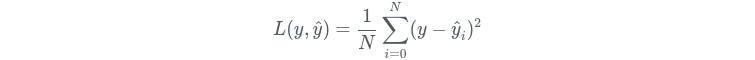
The predict method would simply use the prediction function to compute the predicted value of y given a value for X, using the model states.
4 Likes