
Hi,
When iterating several times the nested cross-validation, how to get the best set of hyperparameters that maximize the mean score from the outer loop? For example, a 5-fold inner cv and a 4-fold outer cv, iterated (repeated) 20 times, will give 4x20 = 80 different models. How to pick up the best and save it for future use?
Thanks
Stephane
Hi @sgorsse,
As mentioned by the end of the Evaluation and hyperparameter tuning notebook, what really matters is the stability of the hyperparameters found in the inner cv. If the hyperparameter tuning procedure always select similar values for the hyperparameters, then all is fine. It means that we can deploy a model fit with those hyperparameters and expect that it will have an actual predictive performance close to what we measured in the outer cross-validation.
But it is also possible that some hyperparameters do not matter at all, and as a result in different tuning sessions give different results. In this case, any value will do. This can typically be confirmed by doing a parallel coordinate plot of the results of a large hyperparameter search as seen in this notebook.
From a deployment point of view, one could also chose to deploy all the models found by the outer cross-validation loop and make them vote to get the final predictions. However this can cause operational problems because it uses more memory and makes computing prediction slower, resulting in a higher computational resource usage per prediction.
Dear Arturo,
Thank you very much for your prompt and enlightening answer. I found the idea of deploying all the models found by the outer cross-validation loop very interesting because it would allow to estimate error bars to the predictions (let me know if I am wrong). However, I do not see how to handle such a deployment. Any suggestion or guide would be very much appreciated even though it is a bit beyond the scope of this course.
Stéphane
I found the idea of deploying all the models found by the outer cross-validation loop very interesting because it would allow to estimate error bars to the predictions (let me know if I am wrong).
The outer loop allows you to estimate the variability (or errors bars if you prefer) of the generalization performance, as a normal cross-validation would do. The difference is that the outer loop of a nested cross-validation additionally takes into account the variability of the generalization performance that is due to the choice of a particular set of hyperparameters.
Take for instance the case of this plot at the end of the Regularization of linear regression model notebook:
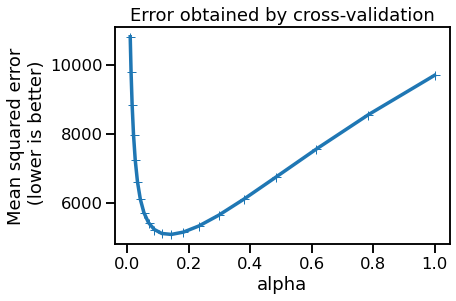
You have a relatively flat sweet spot. It can be described by a horizontal error bar for the equally valid alphas that lie in the range [0.16, 0.18] (computed in the inner loop) and a vertical error bar with the MSE ranging accordingly (computed in the outer loop).
Many thanks, I’ll look at this notebook with lot of interest. To make sure I’ve made myself clear, I would like to estimate an error bar associated to a prediction (model.predict) from unseen data (for example to sample the feature space). So, if I deploy a model and plot Predicted targets vs True targets, how can I associate an error bar (1.96 * std) to each value?
You can also use the quantile loss with gradient boosting which allows you to get additional estimators similarly to the linear quantile regressor.