If you run this snippet of code right after the optimal depth plot you to obtain the validation curve
from sklearn.model_selection import validation_curve
from sklearn.model_selection import cross_validate, ShuffleSplit
cv = ShuffleSplit(n_splits=30, test_size=0.2)
max_depth = [1, 5, 10, 15, 20, 25, 30]
train_scores, test_scores = validation_curve(
DecisionTreeClassifier(),
data_clf[data_clf_columns],
data_clf[target_clf_column],
param_name="max_depth", param_range=max_depth,
cv=cv, n_jobs=2)
plt.plot(max_depth, train_scores.mean(axis=1),
label="Training error")
plt.plot(max_depth, test_scores.mean(axis=1),
label="Testing error")
plt.legend()
plt.xlabel("Maximum depth of decision tree")
plt.ylabel("Accuracy")
_ = plt.title("Validation curve for decision tree")
you will obtain the following output
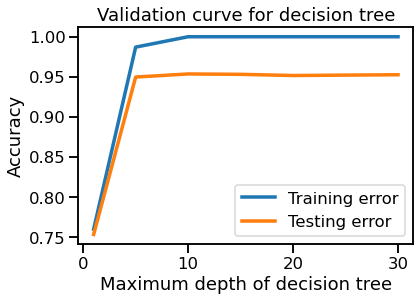
Both the train and test errors become steady above max_depth=7. Indeed, the training errors have a perfect accuracy, meaning that the model is overfitting above this region.
