Is there an error in the answer to M5 wrap-up quiz question 2?
I answered the question correctly but I also checked the answer. Because it was different from what I had done, I copied/pasted the code given in the answer in the notebook to check the result.
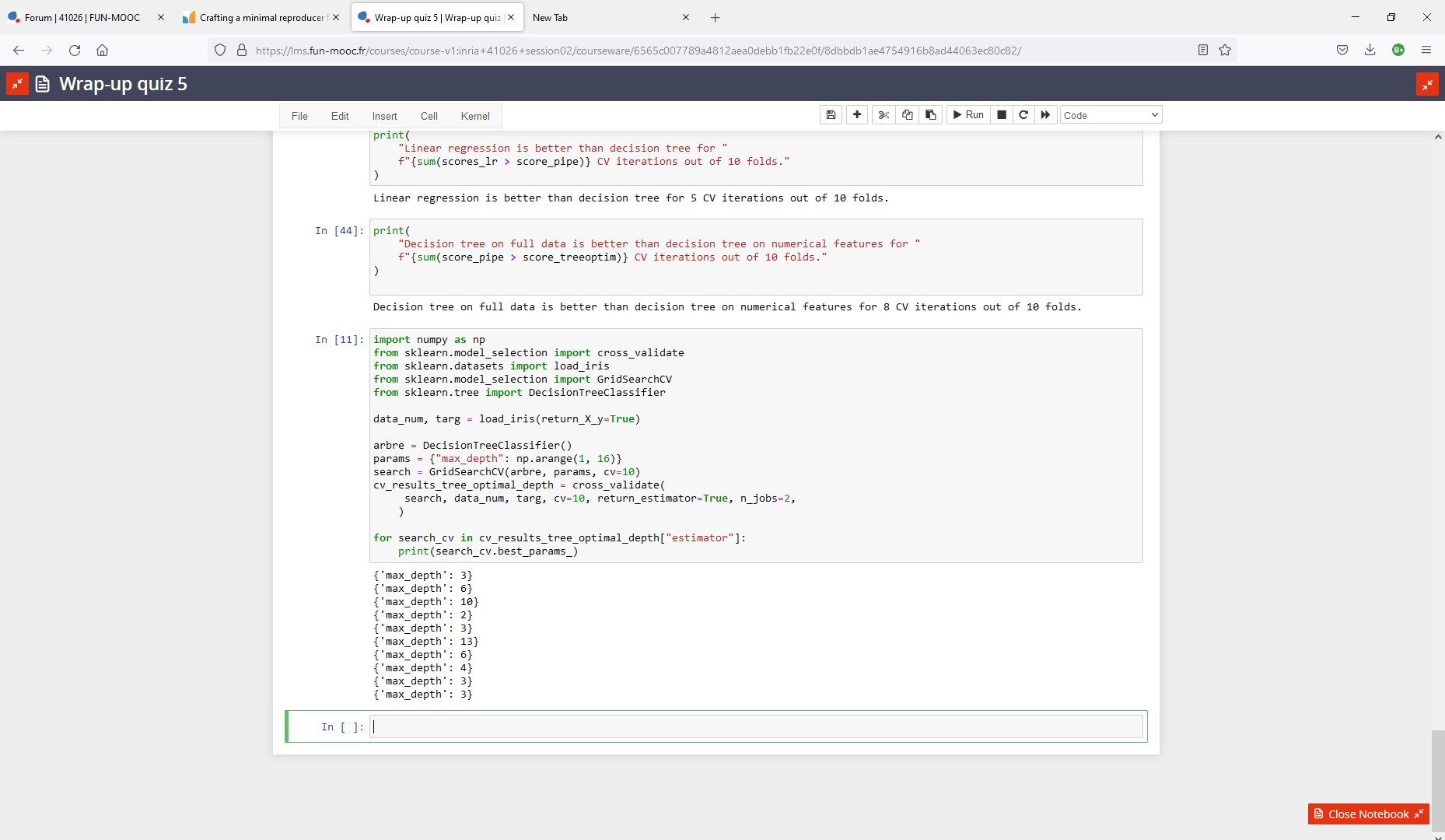
The code proposed is actually generating an error which I do not understand, could you help?
Answer proposed code snippet:
import numpy as np
from sklearn.model_selection import GridSearchCV
params = {"max_depth": np.arange(1, 16)}
search = GridSearchCV(tree, params, cv=10)
cv_results_tree_optimal_depth = cross_validate(
search, data_numerical, target, cv=10, return_estimator=True, n_jobs=2,
)
for search_cv in cv_results_tree_optimal_depth["estimator"]:
print(search_cv.best_params_)
Error message:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/tmp/ipykernel_174/3789612302.py in <cell line: 11>()
10
11 for search_cv in cv_results_tree_optimal_depth["estimator"]:
---> 12 print(search_cv.best_params_)
AttributeError: 'GridSearchCV' object has no attribute 'best_params_'
Thanks in advance for your help!