Hi,
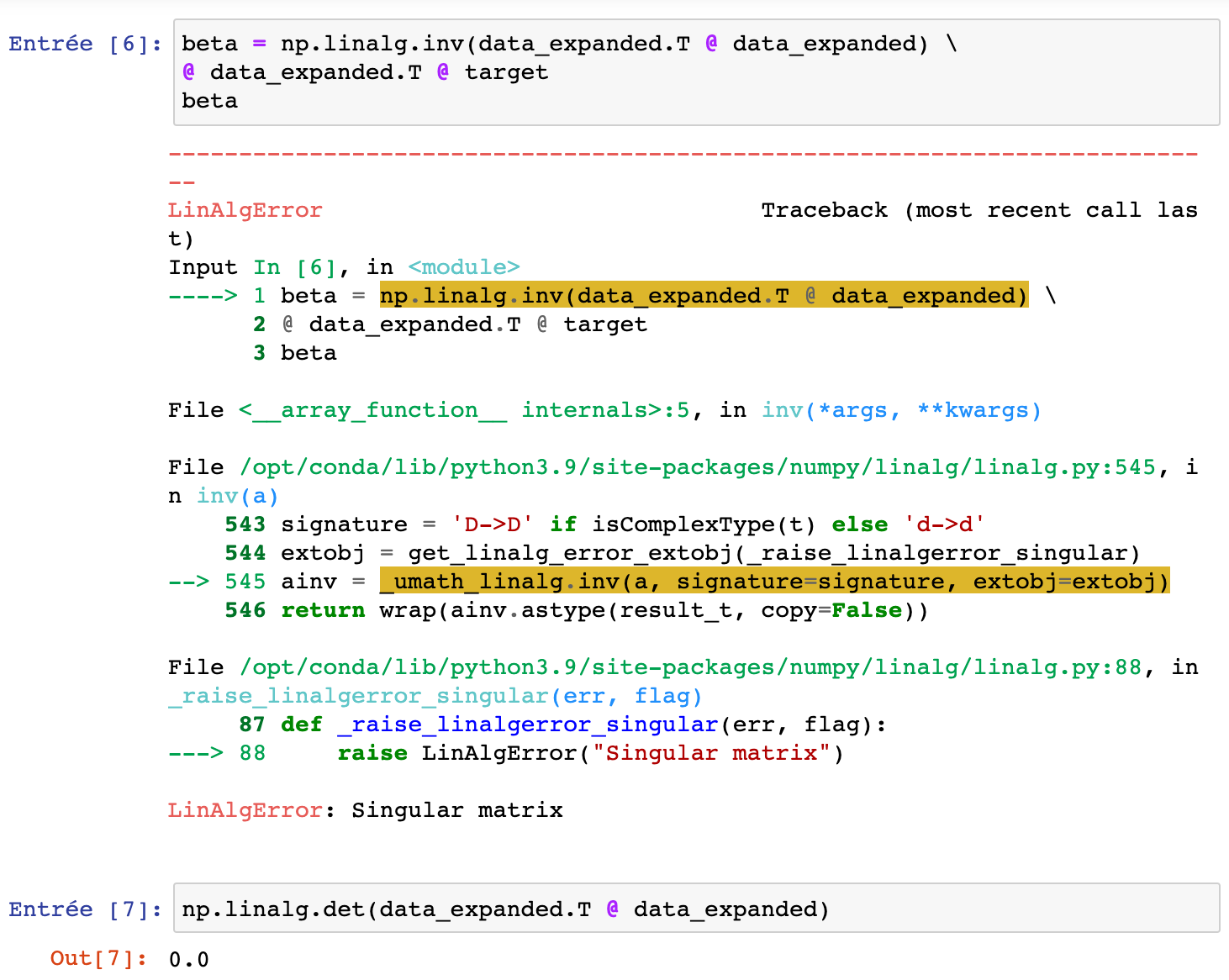
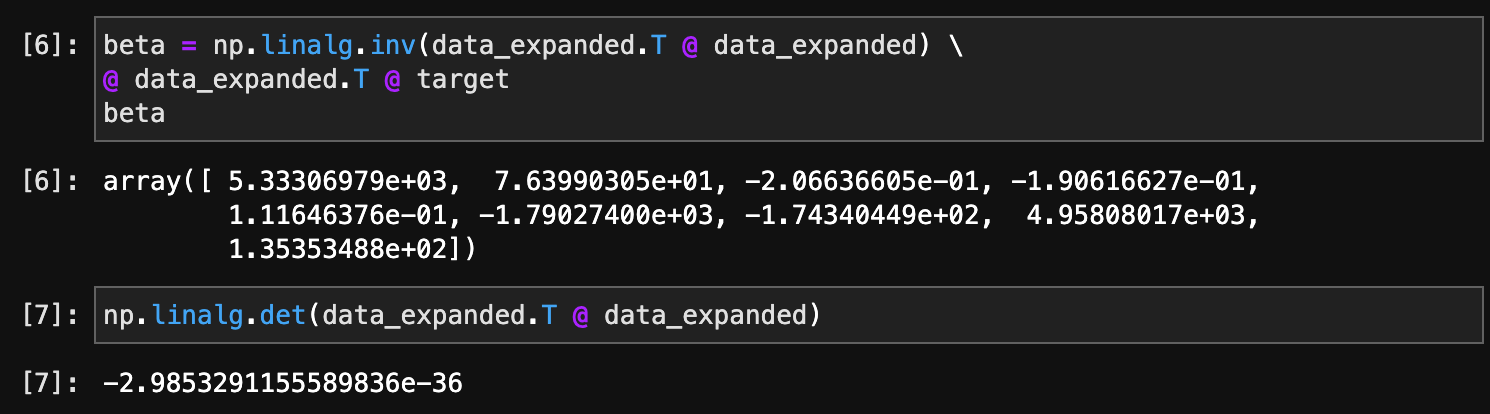
I would have two different outputs for the linear regression coefficients with the same code, either running it on this server or my local server.
From this server…

From my local server…
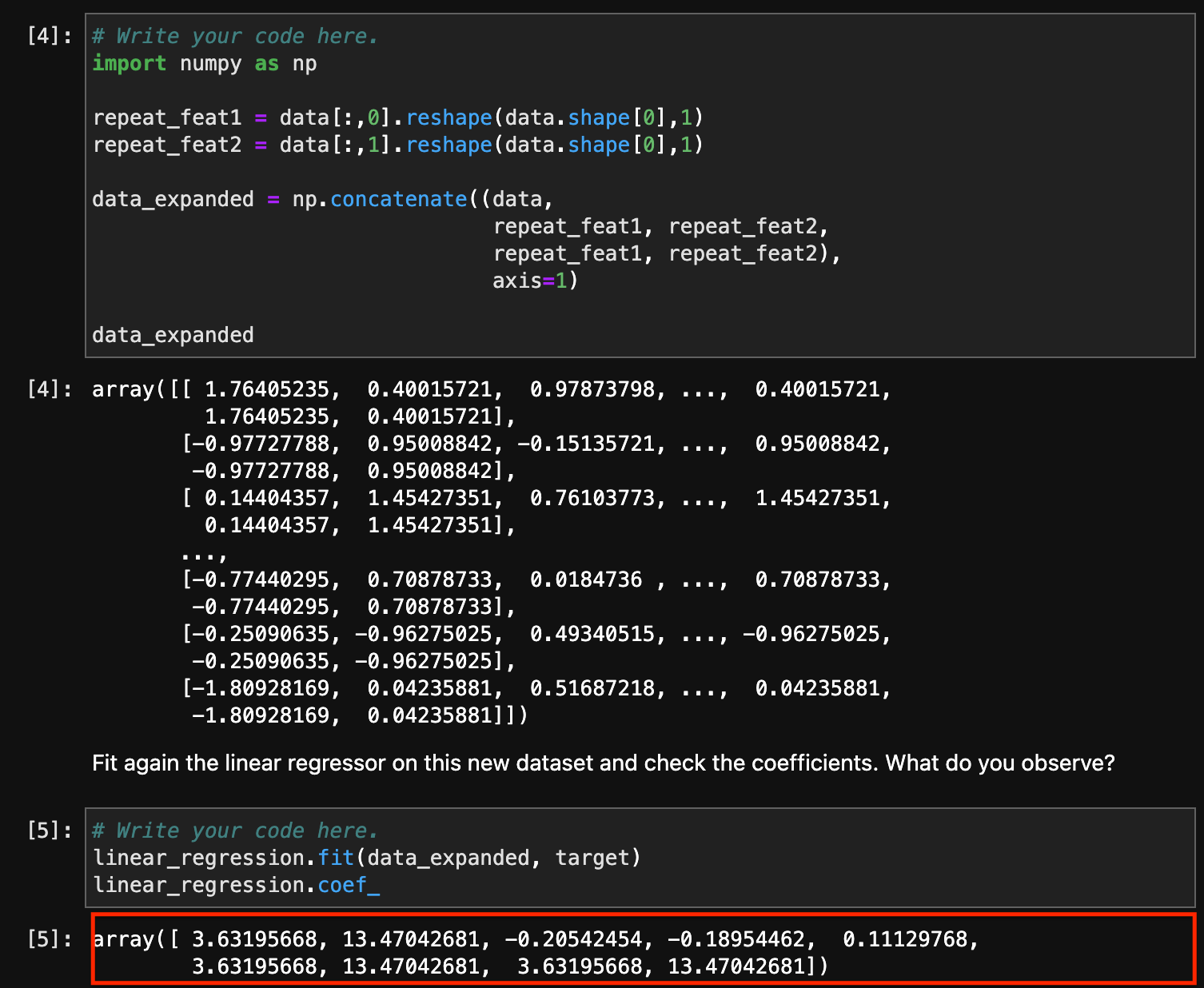
As a matter of fact, I have the same coefficients as with the Ridge regression.
Other things being equal (unless I’m mistaken), do you have any idea of the (possible) reason why I have these two different coefficient outputs?