Dounia2
Bonjour,
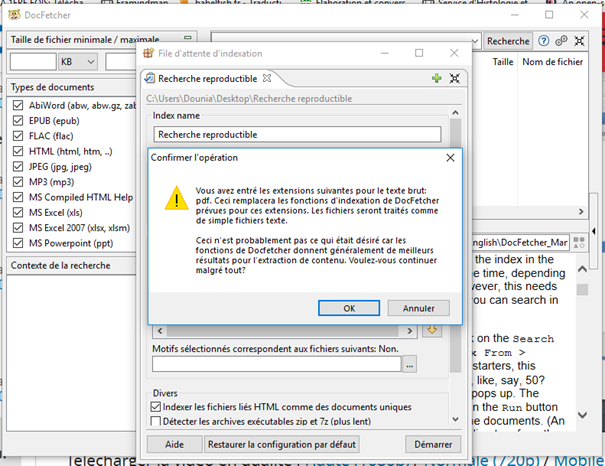
Lorsque j’ai voulu indexer des fichier pdf la première fois, j’ai eu ce message:
Merci d’avance pour votre réponse.

Bonjour,
Lorsque j’ai voulu indexer des fichier pdf la première fois, j’ai eu ce message:
Merci d’avance pour votre réponse.

Bonjour,
Si je comprends bien, vous avez changé les extensions de fichiers que DocFetcher considère par défaut comme des fichiers textes (comme je le fais dans la vidéo didacticielle avec les fichiers org et md) en spécifiant que les fichiers pdf devraient être aussi considérés comme des fichiers textes. Là, en substance, DocFetcher vous indique qu’il sait bien géré les fichiers pdf (c’est-à-dire qu’il va aller regarder dans les parties du fichier qui contiennent effectivement du texte et pas dans celles qui contiennent des « images de textes », comme vous en avez dans les documents scannés) et vous demande si vous êtes bien sûr de votre choix. En général, je ne changerais pas la façon dont DocFetcher traite les pdf. Essayez à nouveau sans indiquer que le pdf doivent aussi être traiter comme des fichiers textes et voyez ce que ça donne.
Christophe
Merci pour votre réponse,
maintenant le programme ne veut plus s’ouvrir?
Il est possible que le programme ait encore un processus en cours d’exécution. Vous pouvez regarder dans le Gestionnaire des tâches / Processus ou bien, solution plus radicale mais aussi plus simple, redémarrer votre ordinateur.
Cordialement,
merci beaucoup,
le problème est réglé